Study Carrels and Content Negotiation
I have begun to create a collection of data sets I call "study carrels". See: http://carrels.distantreader.org/
One of the goals of the collection is to make sure the collection is machine-readable, and to accomplish that goal, it exploits an API native to HTTP, namely, content negotiation. Given a MIME-type and a URI, the HTTP server returns a presentation of the URI in the given type. The server has been configured to know of a number of different types and each type is associated with a different presentation. For example, given the MIME-type application/xhtml+xml, the server will return an XHTML file which is really a bibliography. Given a MIME-type of text/html, the server will return a report describing the data set. Given a MIME-type of application/rdf+xml, the server will return a Linked Data representation.
For example:
curl -L -H "Accept: text/html" \ http://carrels.distantreader.org/subject-americanWitAndHumorPictorial-gutenberg
Or
curl -L -H "Accept: application/xhtml+xml" \ http://carrels.distantreader.org/subject-americanWitAndHumorPictorial-gutenberg
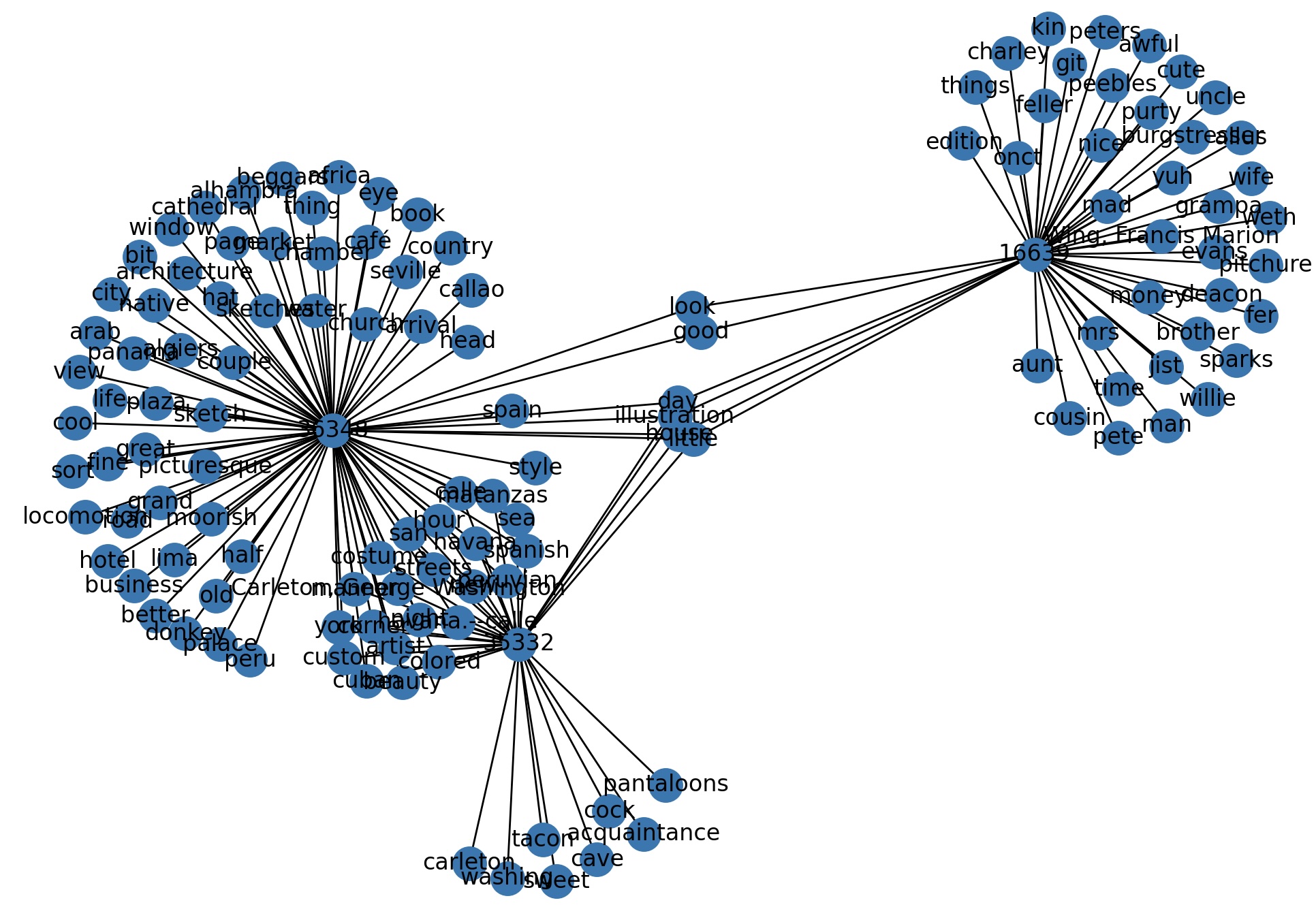
I have written three short Python scripts demonstrating how content negotiation can be exploited. The first visualizes the content of the study carrel as a network graph. More specifically, the MIME-type of application/gml is sent to the server, a Graph Markup Language file is returned, and finally the file is rendered as an image. See carrel2graph.py.
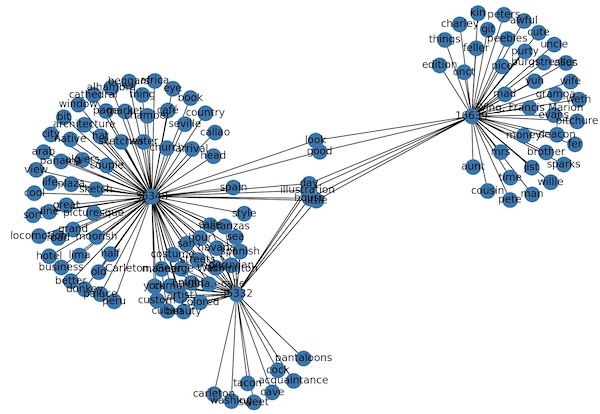
visualization of a study carrel in the form of a network graph
{kind=link}
As a second example, the MIME-type of application/json is specified, and the script ultimately returns a tab-delimited stream containing authors, titles, and URLs of the items in the data set. This stream can be saved to a file and imported into a spreadsheet program for more detailed analysis. See carrel2tsv.py.
The third script -- list-rdf.py -- returns a list of URIs pointing to Linked Data representations of each study carrel in the collection. These URIs and all their content could then be imported into and RDF triple store for the purposes of supporting the Semantic Web.
Here's the point. As a librarian, I desire to create collections and provide services against them. My collection is a set of data sets -- consistently structured amalgamations of information. By putting these collections on the Web and taking advantages of HTTP's native APIs, I do not have to write special software that will eventually break. Moreover, robots can crawl the collection and people can write interesting applications against it. Thus, I support services. As long as the server is running, the collection will be usable. No broken links. No software to be upgraded. Very little maintenance required. 'Sounds sustainable to me.
Note to self: Implement a call to the root of the domain which returns a list of all the collection's identifiers -- URIs
P.S. For a good time, try this one to download a study carrel:
curl -L -H "Accept: application/zip" \ http://carrels.distantreader.org/subject-americanWitAndHumorPictorial-gutenberg > index.zip
Creator: Eric Lease Morgan <emorgan@nd.edu>
Source: I believe I originally shared this on the Code4Lib mailing list.
Date created: 2024-04-30
Date updated: 2024-04-30
Subject(s): study carrels;
URL: https://distantreader.org/blog/study-carrels-and-content-negotiation/