Whenever you have a hammer, everything begins to look like a nail: Hypernyms
Whenever you have a hammer, everything begins to look like a nail, and my newest hammer outputs network graphs describing sets of words and their associated hypernyms.
As a librarian, I am always interested in the concept of aboutness; very often I ask myself, "What is this item or corpus about?" Traditionally, librarians read content, identify themes, peruse a controlled vocabulary for authorized themes, and make assignments accordingly. A more modern technique might be to calculate statistically significant words using an algorithm like Term-Frequency Inverse Document Frequency (TFIDF). Another approach might be to apply topic modeling to a corpus, observe the resulting topics, and identify aboutness terms. I have used all of these techniques, many times.
My latest techique is to appy the concept of hypernms to sets of words. For all intents and purposes, hypernyms are broader terms of given terms. For example, given the terms "January" and "Febrary" a broader term might be "month". Similarly, given the terms "France" and "Germany" a broader term might be "country". Luckily, the venerable tool called WordNet implements (models) the concept of hypernyms. Given two WordNet things (called "synsets"), it is possible to compute their closest hypernym. I can repeat this process for a given lexicon (a set of words of interest), and output the result as a network graph. Thus, my new hammer was born, hypernyms.py. Given a lexicon, hypernyms.py: 1) identifies a synset for each word, 2) compares the resulting synset with every other synset, 3) finds the closest hypernym, and 4) outputs a graph modeling language file where nodes are the lexicon words or hypernyms, and edges are the floating point numbers denoting the distances between the nodes.
As an example, I applied this technique to the results of topic modeling. As you may or may not know, topic modeling is an unsupervised machine learning process used to enumerate latent themes in a corpus. The result of topic modeling are lists of themes where each theme is a list of words. These words are close to each other in the given corpus, and therefore are considered topics. For example, if I topic model Homer's Iliad and Odyssey, then the resulting themes/topics might be listed like this:
themes weights features
house 1.08442 house men ulysses father see home took made
trojans 0.40099 trojans spear hector achaeans fight jove ships...
achilles 0.18074 achilles peleus priam hector city women body r...
agamemnon 0.11047 agamemnon ships achaeans atreus nestor king jo...
sea 0.10438 sea ship men circe wind island water cave
horses 0.10101 horses menelaus diomed agamemnon nestor tydeus...
ulysses 0.09161 ulysses telemachus suitors penelope house euma...
alcinous 0.03744 alcinous phaeacians clothes ulysses stranger t...
The student, researcher, or scholar might then take all of these words as their lexicon, compare them to each other to identify hypernyms, output as a network graph, and visualize the results. In the following visualization, the original keywords are in black, and the computed hypernyms are red. Thus, another way to interpret the topic model is to say Homer's Iliad and Odyssey are about mythical beings, groups, persons, etc.:
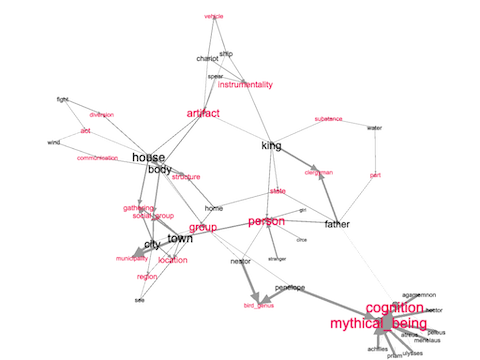
visualizing relationships between keywords (in black) and hypernyms (in red)
Applying a technique called modularity to the graph, one can enumerate clusters of nodes, and visualizing such things brings the beings, groups, and persons together:
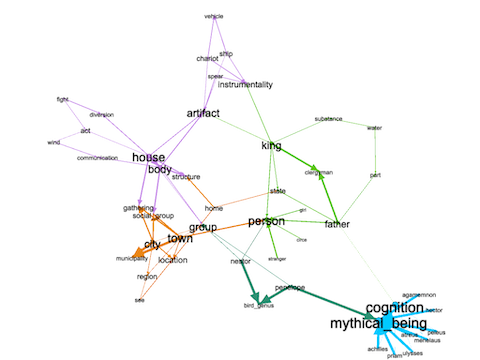
visualizing mathematical modularities (clusters) of keywords and hypernyms
In summary, modeling text in terms of hypernyms is a quick and easy way to grasp the aboutness of an text. The script -- hypernyms.py -- can be applied to any list of words. Such words might be the N most frequent words in a text, a set of computed keywords, a list of named-entities, etc. Fun with data science applied to words. The script, a sample lexicon, a graphic modeling language file, a Gephi file, and a couple of images are all included in the attached file -- hypernyms.zip . Enjoy.
Creator: Eric Lease Morgan <emorgan@nd.edu>
Source: This is the original source of this publication.
Date created: 2023-11-06
Date updated: 2023-11-06
Subject(s): hypernyms; hacks;
URL: https://distantreader.org/blog/hypernyms/