Industrial-Strength
Natural Language
Processing
in Python
Get things done
spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It's easy to install, and its API is simple and productive.
Blazing fast
spaCy excels at large-scale information extraction tasks. It's written from the ground up in carefully memory-managed Cython. If your application needs to process entire web dumps, spaCy is the library you want to be using.
Awesome ecosystem
In the five years since its release, spaCy has become an industry standard with a huge ecosystem. Choose from a variety of plugins, integrate with your machine learning stack and build custom components and workflows.
Edit the code & try spaCy
# pip install -U spacy # python -m spacy download en_core_web_sm import spacy # Load English tokenizer, tagger, parser and NER nlp = spacy.load("en_core_web_sm") # Process whole documents text = ("When Sebastian Thrun started working on self-driving cars at " "Google in 2007, few people outside of the company took him " "seriously. “I can tell you very senior CEOs of major American " "car companies would shake my hand and turn away because I wasn’t " "worth talking to,” said Thrun, in an interview with Recode earlier " "this week.") doc = nlp(text) # Analyze syntax print("Noun phrases:", [chunk.text for chunk in doc.noun_chunks]) print("Verbs:", [token.lemma_ for token in doc if token.pos_ == "VERB"]) # Find named entities, phrases and concepts for entity in doc.ents: print(entity.text, entity.label_)
Features
- Support for 64+ languages
- 55 trained pipelines for 17 languages
- Multi-task learning with pretrained transformers like BERT
- Pretrained word vectors
- State-of-the-art speed
- Production-ready training system
- Linguistically-motivated tokenization
- Components for named entity recognition, part-of-speech tagging, dependency parsing, sentence segmentation, text classification, lemmatization, morphological analysis, entity linking and more
- Easily extensible with custom components and attributes
- Support for custom models in PyTorch, TensorFlow and other frameworks
- Built in visualizers for syntax and NER
- Easy model packaging, deployment and workflow management
- Robust, rigorously evaluated accuracy
New in v3.0Transformer-based pipelines, new training system, project templates & more
spaCy v3.0 features all new transformer-based pipelines that bring spaCy's accuracy right up to the current state-of-the-art. You can use any pretrained transformer to train your own pipelines, and even share one transformer between multiple components with multi-task learning. Training is now fully configurable and extensible, and you can define your own custom models using PyTorch, TensorFlow and other frameworks. The new spaCy projects system lets you describe whole end-to-end workflows in a single file, giving you an easy path from prototype to production, and making it easy to clone and adapt best-practice projects for your own use cases.
From the makers of spaCyProdigy: Radically efficient machine teaching
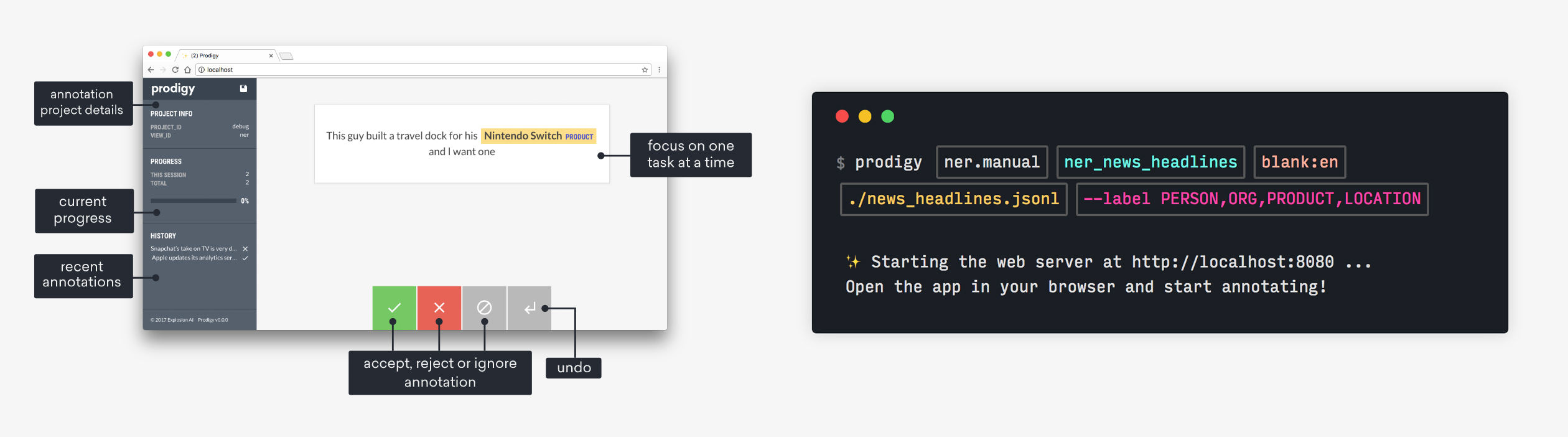
Prodigy is an annotation tool so efficient that data scientists can do the annotation themselves, enabling a new level of rapid iteration. Whether you're working on entity recognition, intent detection or image classification, Prodigy can help you train and evaluate your models faster.
Reproducible training for custom pipelines
spaCy v3.0 introduces a comprehensive and extensible system for configuring your training runs. Your configuration file will describe every detail of your training run, with no hidden defaults, making it easy to rerun your experiments and track changes. You can use the quickstart widget or the init config command to get started, or clone a project template for an end-to-end workflow.
# This is an auto-generated partial config. To use it with 'spacy train'
# you can run spacy init fill-config to auto-fill all default settings:
# python -m spacy init fill-config ./base_config.cfg ./config.cfg
[paths]
train = null
dev = null
[system]
gpu_allocator = null
[nlp]
lang = "en"
pipeline = []
batch_size = 1000
[components]
[components.tok2vec]
factory = "tok2vec"
[components.tok2vec.model]
@architectures = "spacy.Tok2Vec.v2"
[components.tok2vec.model.embed]
@architectures = "spacy.MultiHashEmbed.v2"
width = ${components.tok2vec.model.encode.width}
attrs = ["ORTH", "SHAPE"]
rows = [5000, 2500]
include_static_vectors = false
[components.tok2vec.model.encode]
@architectures = "spacy.MaxoutWindowEncoder.v2"
width = 96
depth = 4
window_size = 1
maxout_pieces = 3
[corpora]
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 2000
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0
[training]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
[training.optimizer]
@optimizers = "Adam.v1"
[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2
[training.batcher.size]
@schedules = "compounding.v1"
start = 100
stop = 1000
compound = 1.001
[initialize]
vectors = null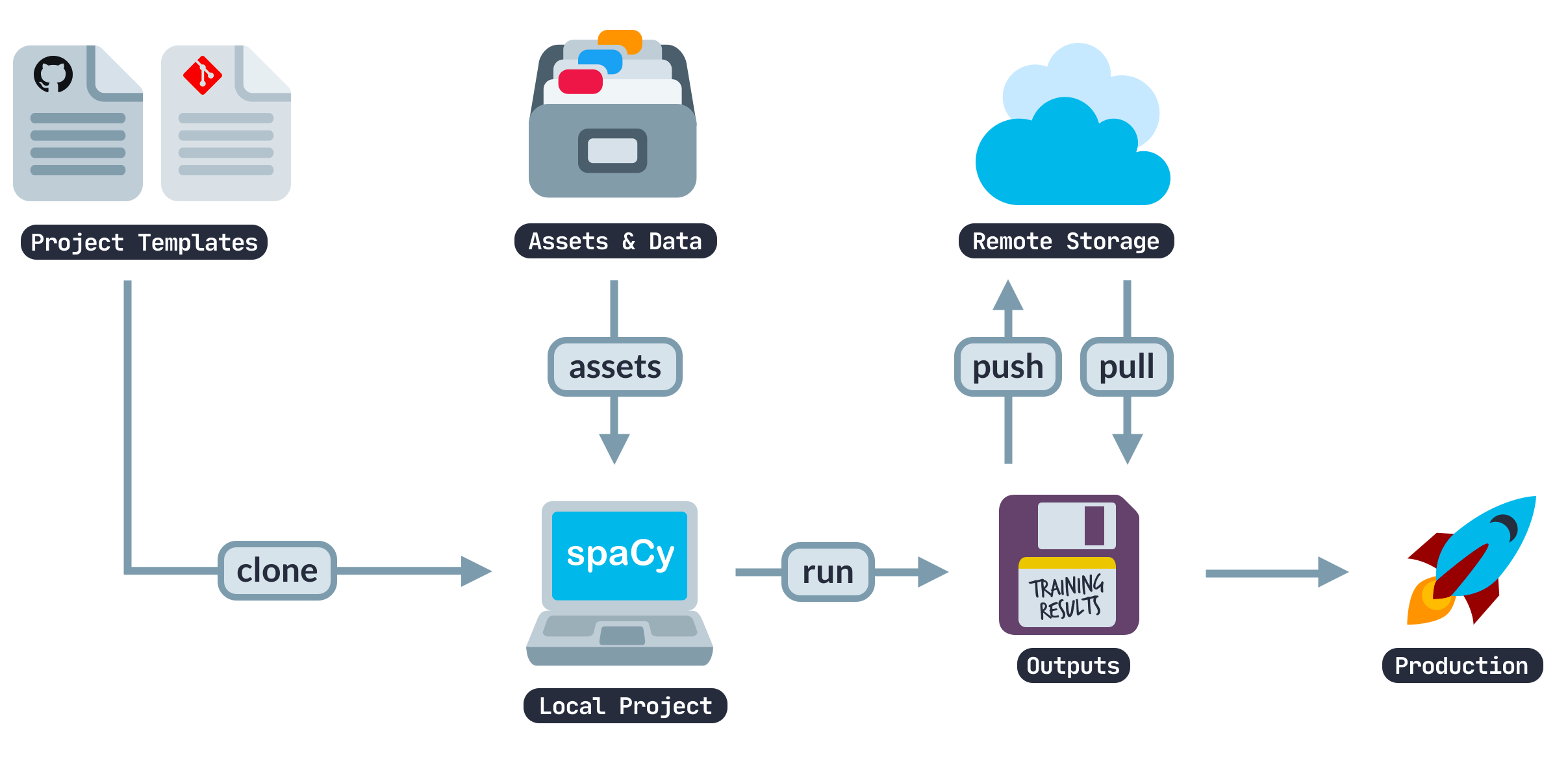
End-to-end workflows from prototype to production
spaCy's new project system gives you a smooth path from prototype to production. It lets you keep track of all those data transformation, preprocessing and training steps, so you can make sure your project is always ready to hand over for automation. It features source asset download, command execution, checksum verification, and caching with a variety of backends and integrations.
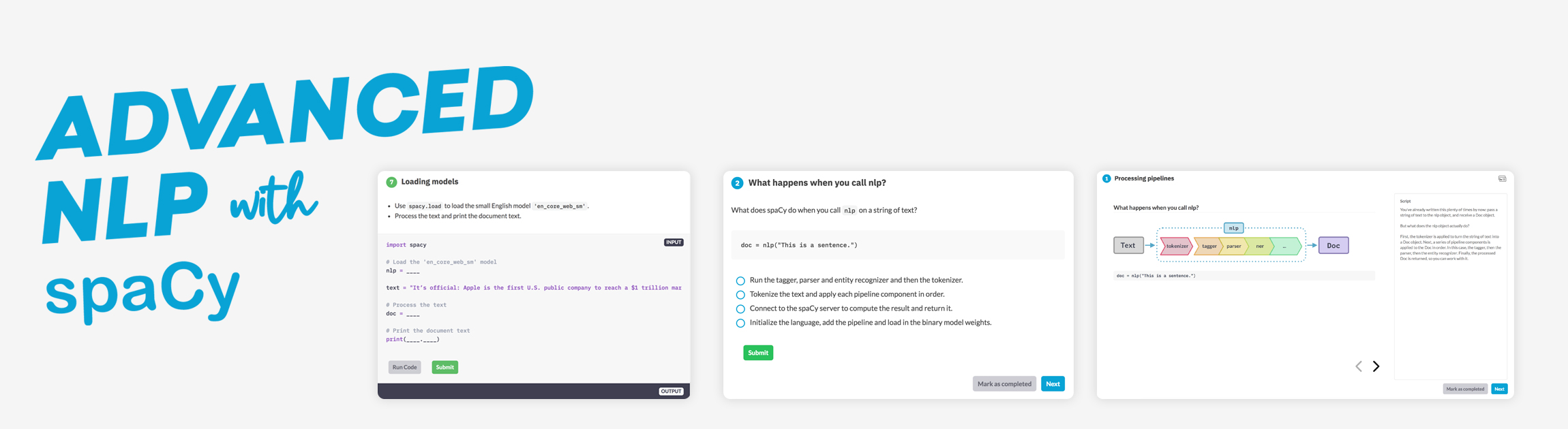
In this free and interactive online course you’ll learn how to use spaCy to build advanced natural language understanding systems, using both rule-based and machine learning approaches. It includes 55 exercises featuring videos, slide decks, multiple-choice questions and interactive coding practice in the browser.
Benchmarks
spaCy v3.0 introduces transformer-based pipelines that bring spaCy's accuracy right up to the current state-of-the-art. You can also use a CPU-optimized pipeline, which is less accurate but much cheaper to run.
| Pipeline | Parser | Tagger | NER |
|---|---|---|---|
en_core_web_trf (spaCy v3) | 95.1 | 97.8 | 89.8 |
en_core_web_lg (spaCy v3) | 92.0 | 97.4 | 85.5 |
en_core_web_lg (spaCy v2) | 91.9 | 97.2 | 85.5 |
Full pipeline accuracy on the OntoNotes 5.0 corpus (reported on the development set).
| Named Entity Recognition System | OntoNotes | CoNLL ‘03 |
|---|---|---|
| spaCy RoBERTa (2020) | 89.8 | 91.6 |
| Stanza (StanfordNLP)1 | 88.8 | 92.1 |
| Flair2 | 89.7 | 93.1 |
Named entity recognition accuracy on the
OntoNotes 5.0 and
CoNLL-2003 corpora. See
NLP-progress for
more results. Project template:
benchmarks/ner_conll03. 1. Qi et al. (2020). 2. Akbik et al. (2018).