In this blog post I will go into the more technical details of SolrWayback and the new version 4.0 release. The whole frontend GUI was rewritten from scratch to be up to date with 2020 web-applications expectations along with many new features implemented in the backend. I recommend reading the frontend blog post first. The frontend blog post has beautiful animated gifs demonstrating most of the features in SolrWayback.

Live demo of SolrWayback
You can access a live demo of SolrWayback here.
Thanks to National Széchényi Library of Hungary for providing the SolrWayback demo site!
Back in 2018…
The open source SolrWayback project was created in 2018 as an alternative to the existing webarchive frontend applications at that time. At the Royal Danish Library we were already using Blacklight as search frontend. Blacklight is an all purpose Solr frontend application and is very easy to configure and install by defining a few properties such as Solr server url, fields and facet fields. But since Blacklight is a generic solr-frontend it had no special handling of the rich datastructure we had in Solr. Also the binary data such as images and videos are not in Solr, so integration to the WARC-file repository can enrich the experience and make playback possible, since Solr has enough information to work as CDX server also.
Another interesting frontend was the Shine frontend. It was custom tailored for the Solr index created with WARC-indexer and had features such as Trend analysis (n-gram) visualization of search results over time. The showstopper was that Shine was using an older version the Play-framework and the latest version of the Play-framework was not backwards compatible to the maintained branch of the Play-framework. Upgrading was far from trivial and would require a major rewrite of the application. Adding to that, the frontend developers had years of experience with the larger more widely used pure javascript-frameworks. The weapon of choice by the frontenders for SolrWayback was the VUE JS framework. Both SolrWayback 3.0 and the new rewritten SolrWayback 4.0 had the frontend developed in VUE JS. If you have skills in VUE JS and interest in SolrWayback your collaboration will be appriciate 🙂
WARC-Indexer. Where the magic happens!
WARC-files are indexed into Solr using the WARC-Indexer. The WARC-Indexer reads every WARC record,extracts all kind of information and splits this into up to 60 different fields. It uses Tika to parse all the different Mime types that can be encountered in WARC-files. Tika extract the text from HTML, PDF, Excel, Word documents etc. It also extracts metadata from binary documents if present. The metadata can include created/modified time, title, description, author etc. For images meta-data it can also width/height or exif information such as latitude/longitude. The binary data themselves are not stored in Solr but for every record in the warc-file there is a record in Solr. This also includes empty records such as HTTP 302 (MOVED) with information about the new URL.
WARC-Indexer. Paying the price up front…
Indexing a large amount of warc-files require massive amounts of CPU, but is easily parallelized as the warc-indexer takes a single warc-file as input. Indexing 700 TB (5.5M WARC files) of warc-files took 3 months using 280 CPUs to give an idea of the requirements.
When the existing collection is indexed, it is easier to keep up with the incremental growth of the collection. So this is the drawback when using SolrWayback on large collections: The Warc-files have to be indexed first.
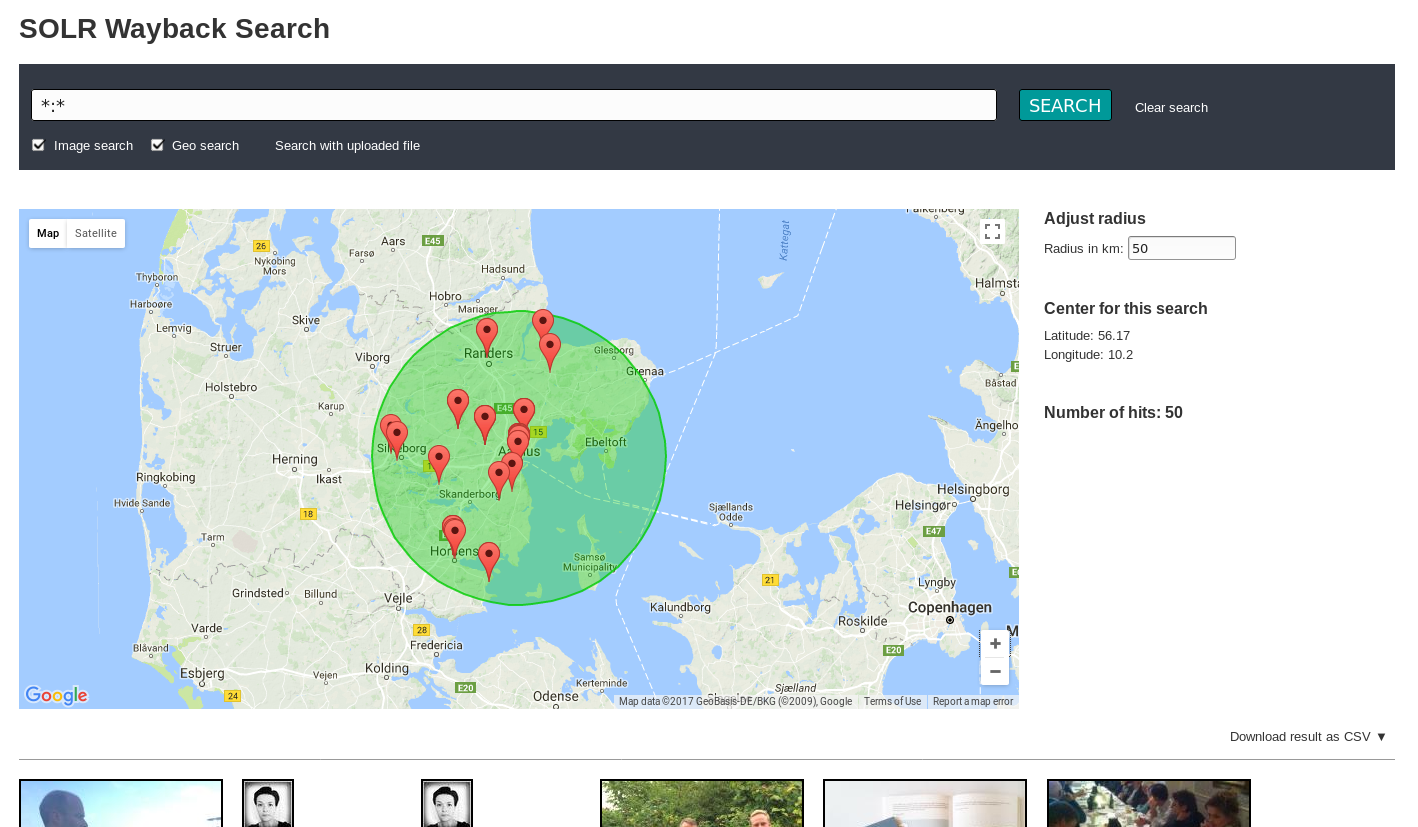
Solr provides multiple ways of aggregating data, moving common netarchive statistics tasks from slow batch processing to interactive requests. Based on input from researchers, the feature set is continuously expanding with aggregation, visualization and extraction of data.
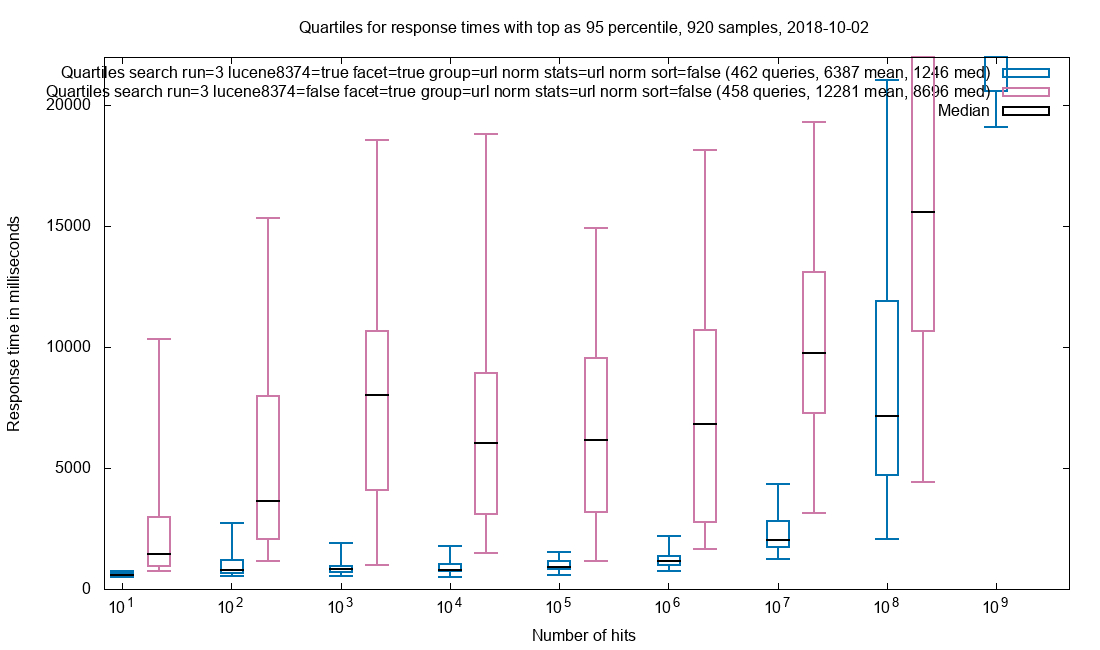
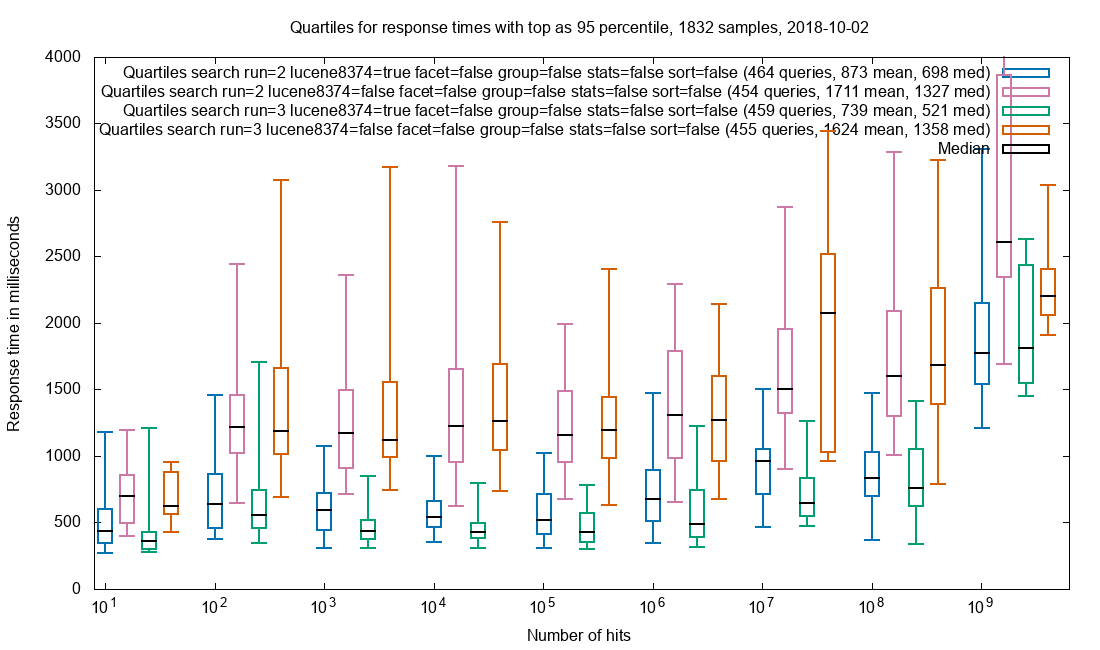
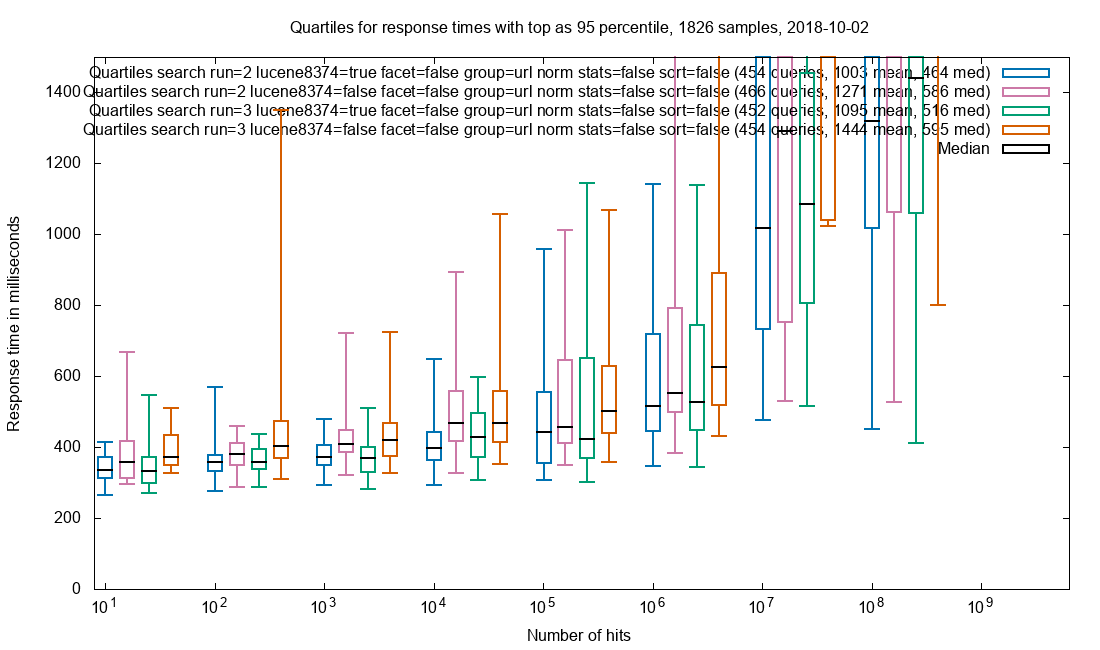
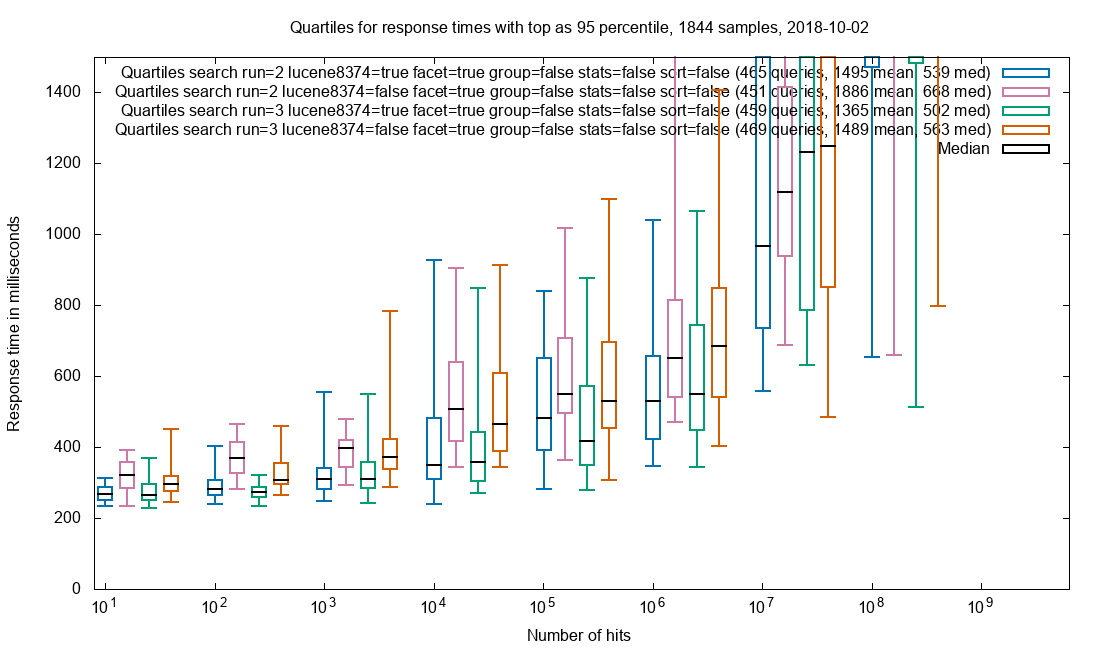
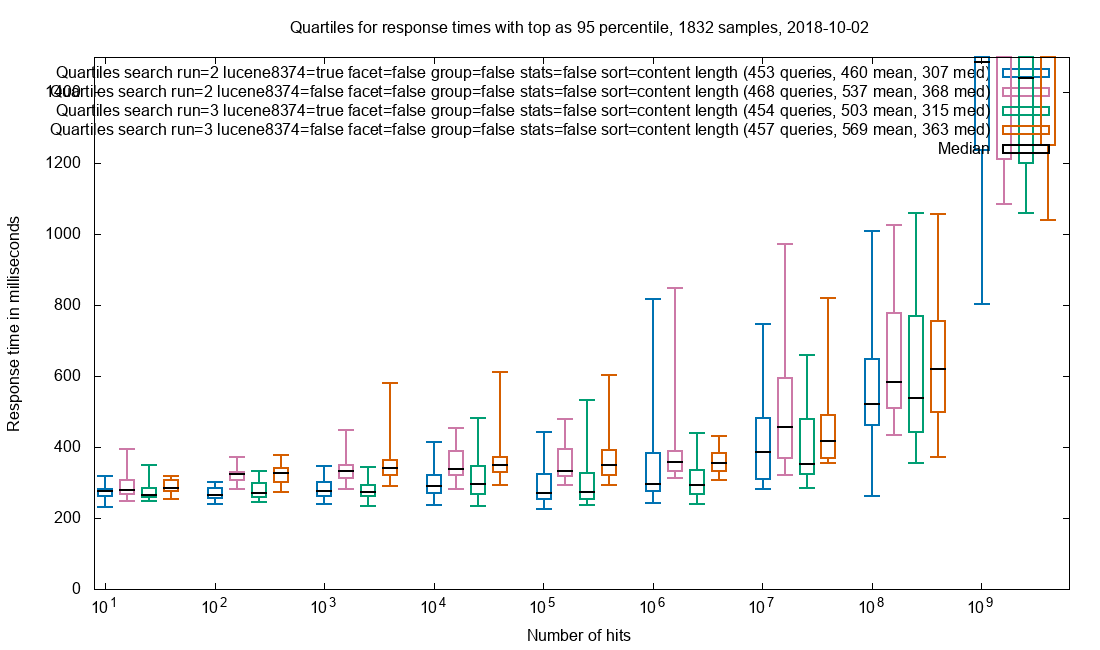
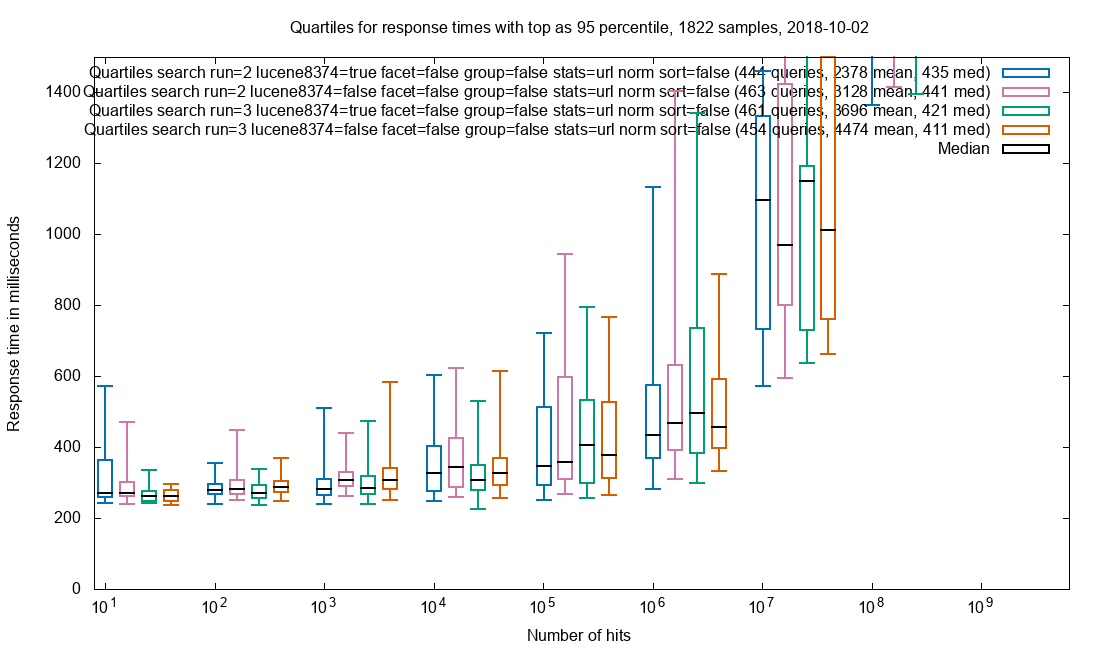
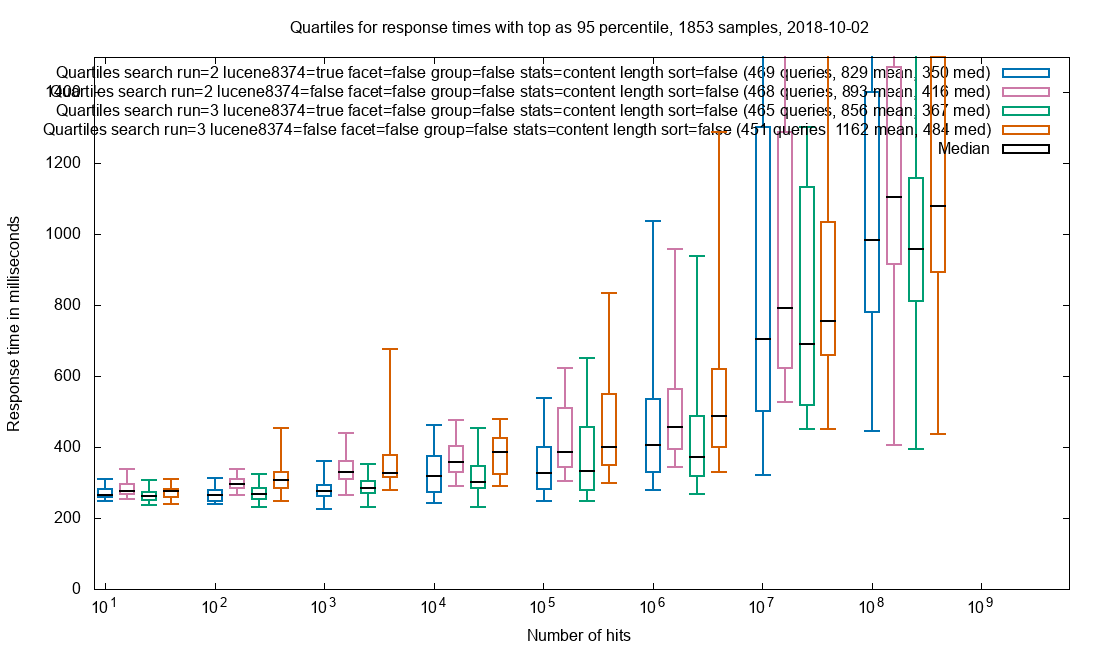
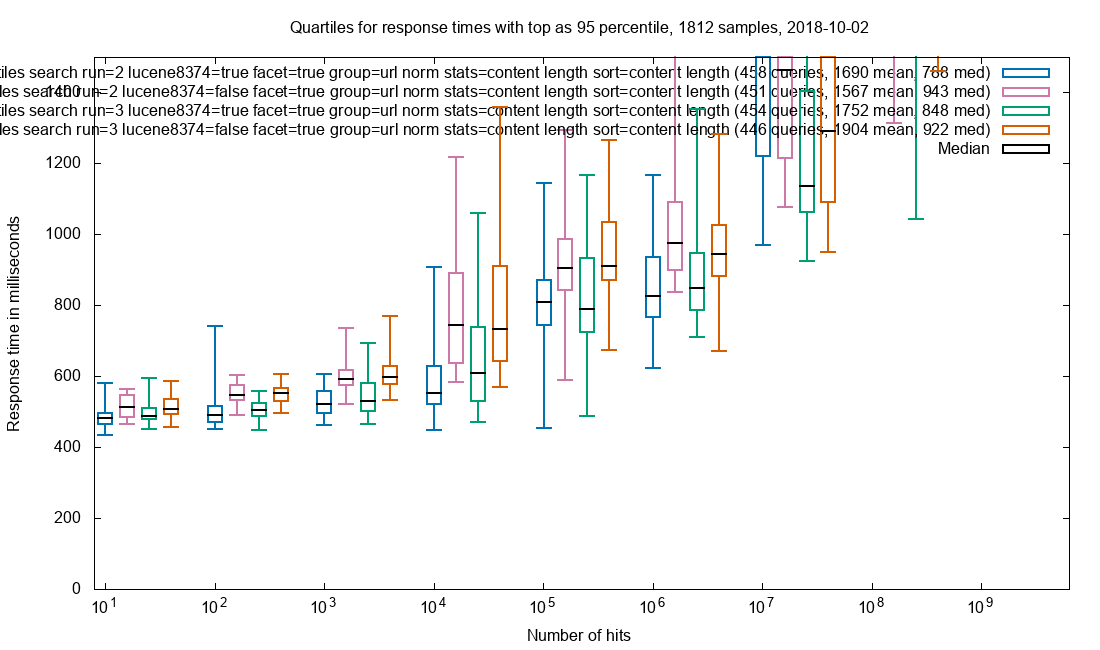
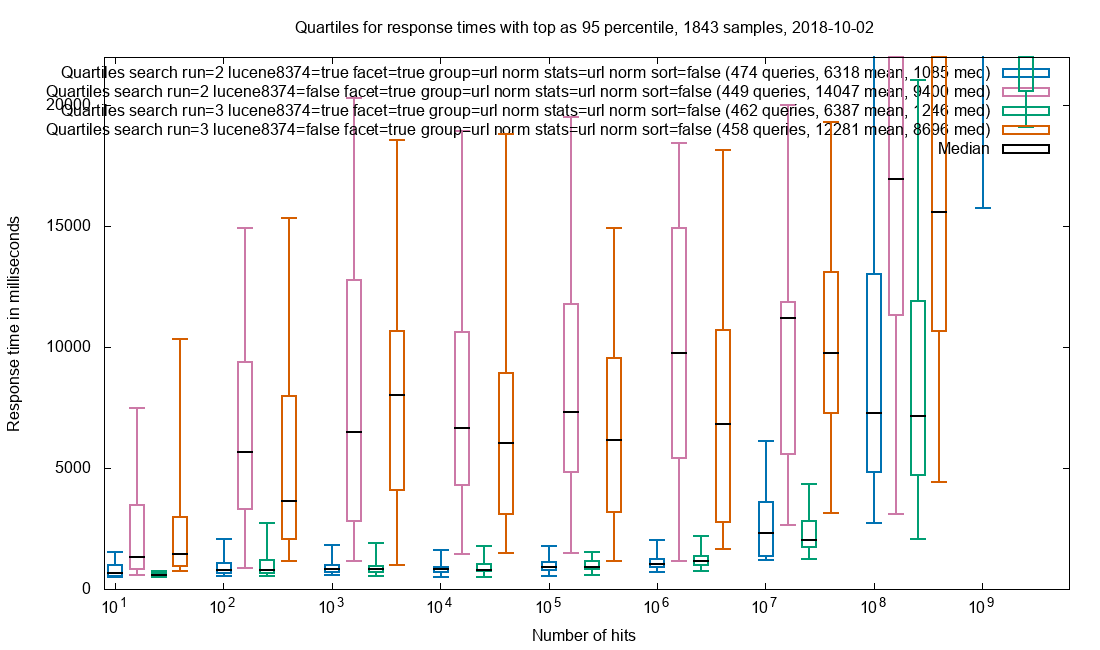
Due to the amazing performance of Solr, the query is often performed in less than 2 seconds in a collection with 32 billion (32*10⁹) documents and this includes facets. The search results are not limited to HTML pages where the freetext is found, but every document that matches the search query. When presenting the results each document type has custom display for that mime-type.
HTML results are enriched with showing thumbnail images from page as part of the result, images are shown directly, and audio and video files can be be play directly from the results list with an in-browser player or downloaded if the browser does not support that format.
Solr. Reaping the benefits from the Warc-indexer
The SolrWayback java-backend offers a lot more than just sending queries to Solr and returning them to the frontend. Methods can aggregate data from multiple Solr queries or directly read WARC entries and return the processed data in a simple format to the frontend. Instead of re-parsing the warc files, which is a very tedious task, the information can be retreived from Solr, and the task can be done in seconds/minutes instead of weeks.
See the frontend blog post for more feature examples.
Wordcloud
Generating a wordcloud image is done by extracting text from 1000 random HTML pages from the domain and generate a wordcloud from the extracted text.
Interactive linkgraph
By extracting domains that links to a given domain(A) and also extract outgoing links from that domain(A) you can build a link-graph. Repeating this for new domains found gives you a two-level local linkgraph for the domain(A). Even though this can be 100s of seperate Solr-queries it is still done in seconds on a large corpus. Clicking a domain will highlight neighbors in the graph.
(Try demo:interactive linkgraph)
Large scale linkgraph
Extraction of massive linkgraphs with up to 500K domains can be done in hours. Link graph example from the Danish NetArchive.
The exported link-graph data was rendered in Gephi and made zoomable and interactive using Graph presenter.
The link-graphs can be exported fast as all links (a href) for each HTML-record are extracted and indexed as part of the corresponding Solr document.
Image search
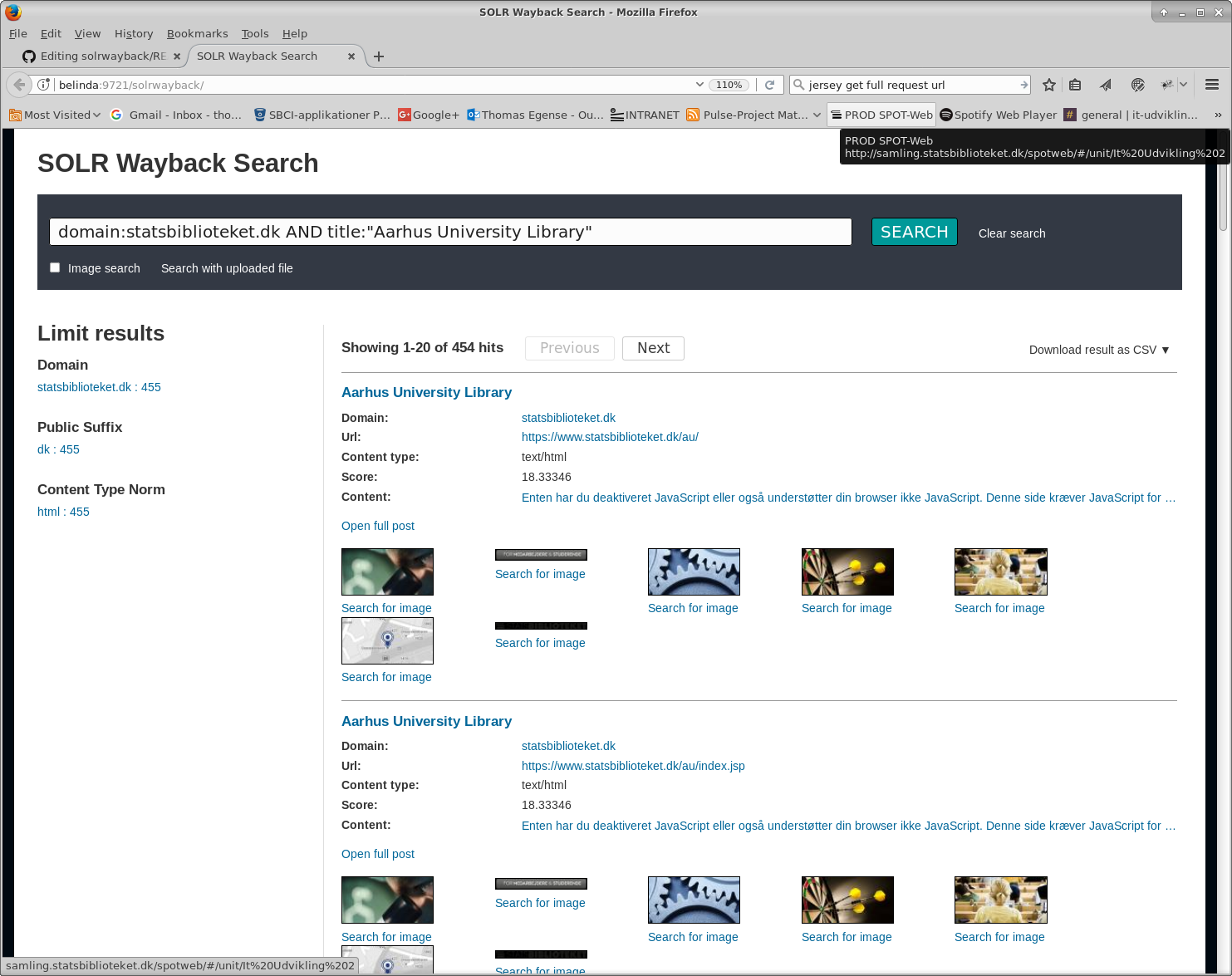
Freetext search can be used to find HTML documents. The HTML documents in Solr are already enriched with image links on that page without having to parse the HTML again. Instead of showing the HTML pages, SolrWayback collects all the images from the pages and shows them in a Google like image search result. Under the assumption that text on the HTML page relates to the images, you can find images for can match the query. If you search for “Cats” in HTML pages , the results found will mostly likely show pictures of cats. The pictures could not be found by just searching for the image documents if no meta data (or image-name) has “Cats” as part of it.
CVS Stream export
You can export result sets with millionsof documents to a CSV file. Instead of exporting all possible 60 Solr fields for each result, you can custom pick which fields to export. This CSV export has been used by several researchers at the Royal Danish Library already and gives them the opportunity to use other tools, such as RStudio, to perform analysis on the data. The National Széchényi Library demo site has disabled CSV export in the SolrWayback configuration, so it can not be tested live.
WARC corpus extraction
Besides CSV export, you can also export a result to a WARC-file. The export will read the Warc-entry for each document in the resultset and copy the WARC-header+ Http-header + payload and create a new Warc-file with all results combined.
Extract a sub-corpus this easy has already shown to be extremely useful for researchers. Examples includes extracting of a domain for a given date range, or query with restriction to a list of defined domains. This export is a 1-1 mapping from the result in Solr to the entries in the WARC-files.
SolrWayback can also perform an extended WARC-export which will include all resources(js/css/images) for every HTML page in the export.
The extended export ensures that playback will also work for the sub-corpus. Since the exported Warc file can become very large, you can use a WARC splitter tool or just split up the export in smaller batches by adding crawl year/month to the query etc. The National Széchényi Library demo site has disabled WARC export in the SolrWayback configuration, so it can not be tested live.
SolrWayback playback engine
SolrWayback has a built-in playback engine, but using it is optional and SolrWayback can be configured to use any other playback engine that uses the same API in URL for playback “/server/<date>/<url>” such as PyWb. It has been a common misunderstanding that SolrWayback forces you to use the SolrWayback playback engine. The demo at National Széchényi Library has configured PyWb as alternative playback engine. Clicking the icon next to the titel for a HTML result will open playback in PyWb instead of SolrWayback.
Playback quality
The playback quality of SolrWayback is an improvement over OpenWayback for the Danish Netarchive, but not as good as PyWb. The technique used is url-rewrite just as PyWb does, and replaces urls according to the HTML specification for html-pages and CSS files. However , SolrWayback does not replace links generated from javascript yet, but this is most likely to be improved in a next major release. It has not been a priority since the content for the The Danish NetArchive is harvested with Heritrix and the dynamic javascript resources are not harvested by Heritrix.
This is only a problem for absolute links, ie. starting with http://domain/… since all relative URL paths will be resolved automatically due to the URL playback API. Relative links that refer to the root of the playback-server will also be resolved by the SolrWaybackRootProxy application which has this sole purpose. It calculates the correct URL from the http-referer tags and redirect back into SolrWayback. The absolute URL from javascript (or dynamic javascript) can result in live leaks. This can be avoided by a HTTP proxy or just adding a white list of urls to the browser. In the Danish Citrix production environment, live leaks are blocked by sandboxing the enviroment. Improving playback is in the pipeline.
The SolrWayback playback has been designed to as authentic as possible without showing a fixed toolbar in top of the browser. Only a small overlay is included in the top left corner, that can be removed with a click, so that you see the page as it was harvested. From playback overlay you can open the calendar and an overview of the resources included by the HTML page along with their timestamps compared to the main HTML page, similar to the feature provided by the archive.org playback engine.
The URL replacement is done up front and fully resolved to an exact WARC file and offset. An HTML page can have 100 of different resources on the page and each of them require an URL lookup for the version nearest to the crawl time of the HTML page. All resource lookups for a single HTML page are batched as a single Solr query, which both improves performance and scalability.
SolrWayback and Scalability
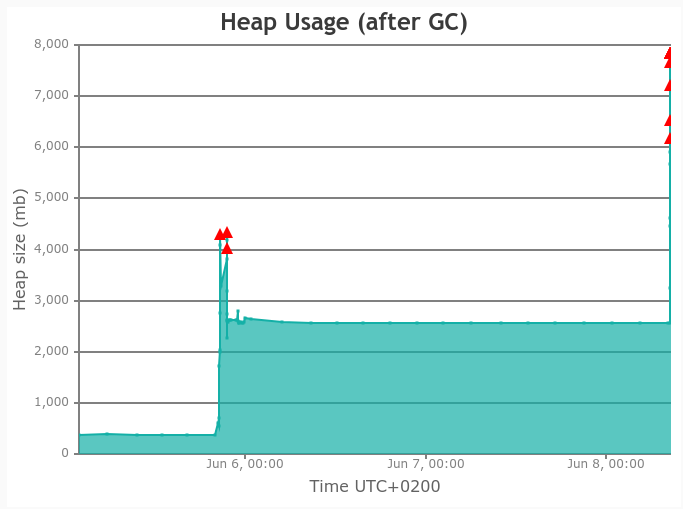
For scalability, it all comes down to the scalability of SolrCloud, which has proven without a doubt to be one of the leading search technologies and is still rapidly improving for each new version. Storing the iindexes on SSD gives substantial performance boosts as well but can be costly. The Danish Netarchive has 126 Solr servers running in a SolrCloud setup.
One of the servers is master and the only one that recieve requests. The Solr master has an empty index but is responsible for gathering the data from the other Solr-services. If the master server also had an index there would be an overhead. 112 of the Solr servers have a 900 GB index with an average of ~300M documents while the last 13 servers currently has an empty index, but it makes expanding the collections easy without any configuration changes. Even with 32 billion documents, the query response times are sub 2 seconds. The result query and the facet query are seperate simultaneous calls and its advantage is that the result can be rendered very fast and the facets will finish loading later.
For very large results in the billions, the facets can take 10 seconds or more, but such queries are not realistic and the user should be more precise in limiting the results up front.


Building new shards
Building of new shards (collection pieces) is done outside the production enviroment and moved into one of the empty Solr servers when the index reaches ~900GB. The index is optimized before it is moved, since no more data will be written to it that would undo the optimization. This will also give a small performance improvement in query times. If the indexing was done directly into the production index, it would also impact response times. The separation of the production and building environment has spared us from dealing with complex problems we would have faced otherwise. It also makes speeding up the index building trivial by assigning more machines/CPU for the task and creating multiple indexes at once.
You can not keep indexing into the same shard forever as this would cause other problems. We found the sweet spot at that time to be ~900GB index size and it could fit on the 932GB SSDs that were available to us when the servers were built. The size of the index also requires more memory of each Solr server and we have allocated 8 GB memory to each. For our large scale webarchive we keep track of which WARC files has been indexed using Archon and Arctica.
Archon is the central server with a database and keeps track of all WARC files and if they have been index and into which shard number.
Arctika is a small workflow application that starts WARC-indexer jobs and query Arctika for next WARC file to process and return the call when it has been completed.
SolrWayback – framework
SolrWayback is a single Java Web application containing both the VUE frontend and Java backend. The backend has two Rest service interfaces written with Jax-Rs. One is responsible for services called by the VUE frontend and the other handles playback logic.
SolrWayback software bundle
Solrwayback comes with an out of the box bundle release. The release contains a Tomcat Server with Solrwayback, a Solr server and workflow for indexing. All products are configured. All that is required is unzipping the zip file and copying the two property-files to your home-directory. Add some WARC-files yourself and start the indexing job.