Date ranges
This is the stub of an index.html file; this file was automatically generated to describe the Distant Reader study carrel ("data set") it represents, specifically, a whole lot of an electronic journal called Sriwijaya Law Review. Even more specifically, this study carrel is a collection of content -- probably journal articles -- harvested and cached from an OAI-PMH repository as imeplemented by Open Journal System (OJS). Why probably? Becuase OJS is typically used to host and publish scholarly open access journal content. The OAI-PMH Data Repository root URL of the journal is http://journal.fh.unsri.ac.id/index.php/sriwijayalawreview/oai, and to browse the respository's content in it's raw form, start at http://journal.fh.unsri.ac.id/index.php/sriwijayalawreview/oai?verb=Identify
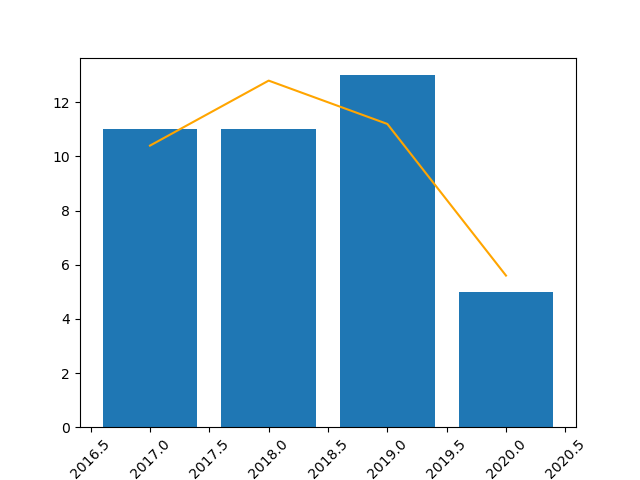
I harvested the content of this study carrel, and it includes content dated as early as 2017 and as late as 2020. There are 40 items ("articles") in the collection for a total of 2,200 words. By comparison, the Bible is about 800,000 words long and Melville's Moby Dick is about 250,000 words long. Now, ask yourself, "To what degree is this collection large or small?" Incidentlly, the collecton has an average Flesch readability score of 43, and based on my experience, scholarly journal articles usually have readability scores in between 50 and 60. The frequency of articles between 2017 and 2020 is visualized below, and now you can address the question, "To what degree has this journal been publishing consistently and to what extent?"
Date ranges
The scope of the collection has been modeled in a number of ways. The most rudimentary models are simple lists of the carrel's items and their bibliographic characteristics (authors, titles, dates, etc.). These models are available in both plain text and JSON formats. The former is easy to read, and the later is more computable. As an example of what can be done with the JSON file, you can quickly and easily garner the scope of the collection by reading the pathfinder.
The scope of the carrel can begin to be illustrated by observing the carrel's unigram, bigram, and computed keyword frequencies. These frequencies take a set of stop words into account, meaning, stop words are not included in the analysis. After observing the word clouds (below) you can begin to address the question, "What is this collection about? God? Knowledge? Truth? Justice? Beauty? If not, then what is it about?"
 unigrams |
 bigrams |
 keywords |
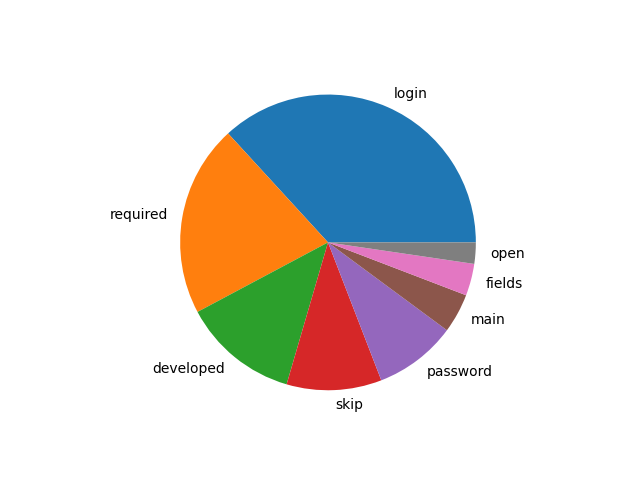
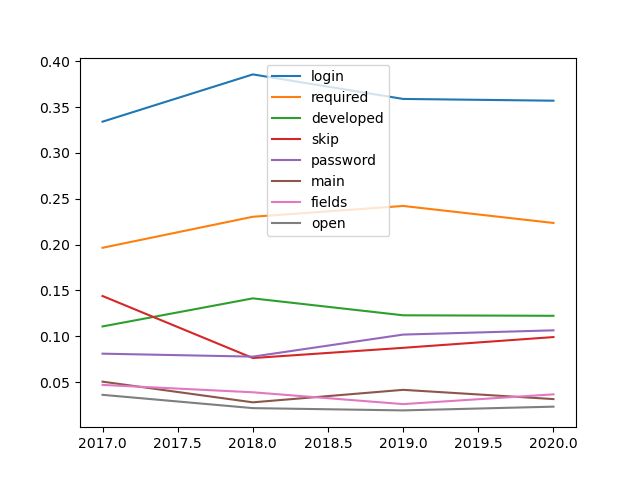
Topic modeling is an additional way to measure the aboutness of a corpus, and topic modeling is just as much of an art as well as a science. That said, after doing a bit of rudimentary topic modeling against this corpus, we might say it is about the following topics, where each topic ought to be read as if it were a hyphenated word made up by the feature words:
| labels | weights | features |
|---|---|---|
| login | 4.94112 | login skip required menu register password open main |
| required | 2.81667 | login required english asterisk navigation footer main universitas |
| developed | 1.70349 | login developed skip home open language forgot register |
| skip | 1.39426 | skip register forgot footer main login password fields |
| password | 1.20884 | password open main menu asterisk systems forgot marked |
| main | 0.57793 | main marked developed menu indonesia bahasa language systems |
| fields | 0.46887 | fields username register main language password site login |
| open | 0.31229 | open keep developed forgot footer site menu login |
Topics
Topics over years
For more detail, see:
Eric Lease Morgan <eric_morgan@infomotions.com>
Date created: 2025-12-23