This note outlines the approach taken by the Department of Economics and Technology in the Berlin City administration to crowd-source a list of priority datasets to make available as open data through an online voting process.
The freeing of public data is a rather new approach, especially in the European continent. Public practice has until recently often been conducted with official secrets and closed documentation. Civil society's request for opening public data files confronts the public administration with unknown challenges. Although most democratic countries have a "Freedom of Information Act" (FOI), this does not mean that they have simple procedures for transparency. Official authorities still control access to information and maintain the power of interpretation. The German FOI law gives the citizens the right to ask for special documents. But because a request for documents is seen as a private interest, applicants are asked to pay a fee in order to obtain the documents. In some fields such as environmental information, a special law permits free access to information about air pollution or water quality. But in other fields, information and data remains unavailable. Public transport organisations, for example, are not willing to open their real time traffic data because of concerns about quality control or how the data might be used. Citizen demand for types of data and information not covered by FOI is growing. People are asking for more information about planning applications and building sites, noise pollution and other issues. Responding to this demand, openness of datasets, distinct from FOI processes can be a tool for more democracy and legitimacy of our political system.
The Department of Economics and Technology in the Berlin City administration was interested to explore the potential of providing open data IT services. Could large amounts of public information be a basis for the state providing data-as-a-service to citizens? If so, what categories and datasets are people really interested in? Berlin could adopt some of the dataset categories used in the data catalogues of cities such as London, Paris or San Francisco to Berlin. But will people in Berlin react to this categorization in the same way? Will they look for the same datasets? Therefore, instead of deciding what open data to focus on by replicating the focus taken in other cities, we asked people in Berlin about their dataset priorities in an (anonymous) online vote: a kind of crowd-sourcing.
The online voting tool used was installed on the city platform Berlin.de (www.berlin.de). Those, who participated in the online voting procedure were not required to register and no facility for comments was provided. The voting site was locked with a barrier to ensure that only one vote came in from each IP-address. This was to prevent the same individual from voting multiple times. The vote was open from September 23rd till October 30th 2010. More than 1,300 voters participated.
The voting consisted of three parts: a list of 20 categories of open data, a question soliciting general interest in open data, and a question about the activities the voter might carry out with open data. In the first section voters could select three categories of main interest out of the 20 available: indicating a first, second and third choice of priorities. The list included categories for: administration data, education data, health data and waste data, among others (see the full list in the Appendix). These categories were selected based on the most used content of the Berlin city portal website, and based on the structure of data catalogues of other cities. Each category was described by three terms to outline the sorts of datasets that every category might contain. For example, pollution involved categories such as respirable dust, CO2, pollen density.
The second part asked voters if they would frequently read open data, and the third part asked the voters if they would work with the public data and edit them for other people. The second and third questions were taken from an open data survey conducted by SAS Deutschland (http://www.sas-navigator.de/content/dokumente/studien/e623/views624/) in June 2010, to allow us to compare our results with that survey. The SAS survey studied general interest in open data in Germany, but did not look at the detailed categories of datasets citizens may be interested in. The survey was performed by a professional demoscopic market researcher. The SAS results are statistically representative of the German population. They found that 88 percent of the people are in favour of the opening of public data files. About 81 percent see open data as a chance for more participation. 69 percent said they would read the open data frequently. And only 16 percent saw any danger in the opening of public files: for example, privacy issues. The SAS representative sample (sample size 1,018) was structured for four age groups: 18 - 29, 30 - 44, 45 - 59 and more than 60 years. This allowed the SAS results to be disaggregated by age and by other demographics.
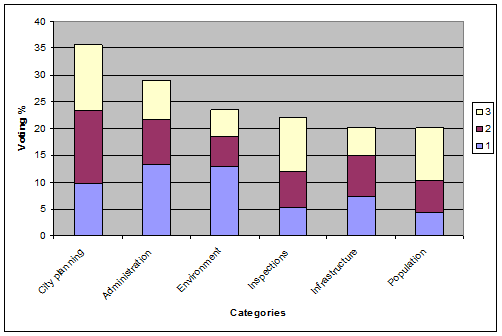
After one week, we had about 1,000 votes and after two weeks about 1,100. By the end, there were 1,338 votes. Not everybody selected three categories, but the odds-on favourites were clear. The results were stable after the first week of voting, i.e. new voters did not significantly alter the final ranking.
The voters elected the "city planning" category with 11.9 percent as the top priority. Second was "administration" with 10.3 percent, at the third place was "environment" with 7.8 percent. Looking at the first, second and third choice voters made of their own priorities we find a good statistical distribution. The order of the list of datasets impacted on voters' choices, but giving voters three choices minimizes the impact of this. Environment was first on the list of options and it had more first-choice votes than City planning which was at the end of the list. However, city planning got more third-choice votes. The voters appeared to give their first-choice votes to more known categories such as "administration" or "environment". It appears that later, when they checked the list in more detail, they found other interesting categories. It is here that we see "inspections" or "population statistics" getting significant second and third-choice votes. .
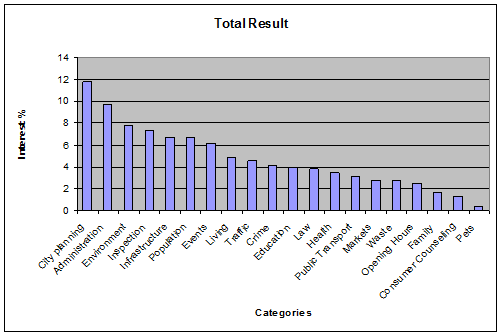
The total result gives an impression of the priority of datasets and highlights the more and less interesting categories for public data. The first five categories cover nearly 50 percent of the interest expressed.
Our second question asked if the users would read open data frequently. More than 92 percent answered "yes". This is much higher than in the SAS representative sample of Germany as a whole. The overall average in that survey was 69 percent. However, in the age group of 18 to 29 years the SAS value was 79 percent, and among the highly educated demographic, this value reached 83 percent. We find the same pattern for the answer to question three "Will you work with these data and edit them for other people?" Our voting exercise received 52.9 percent positive answers. Again, this is much higher than the average in the SAS survey which had 26 percent positive responses. But it is closer to their age group 18-29 with 42 percent positive feedback. This suggests that the profile of our voters may have had some bias.
With this online voting tool, we got advice about which public files to open first. This procedure gave an impression of the more and less interesting categories, ranging from "administration" to "waste", for priorities in freeing public datasets. Five categories cover nearly 50 percent of the voters' interest. But the voters are not typical for the average population. A comparison with a representative survey in the same field shows, that we received votes from a young and highly educated internet user group. This has to be considered when freeing public data files for all citizens. However, crowd-sourcing priorities is still a great chance to engage interested user groups, both with the voting for data categories and in their use. This is a modern contribution to develop our democratic systems in Europe.
In practice, response to the online vote has helped us to start with datasets of public interest. The first datasets on "Geography and City Planning" or "Environment" are available now as machine-readable data. We have also focussed on harvesting "low hanging fruits" i.e., simple datasets with free licences and limited complexity. Starting with such datasets brings early success to support the development of our open data portal: http://daten.berlin.de.
In the next step, we can analyze the monthly user statistics of the data portal in order to extend the content and categories and to match user needs uncovered through web analytics. The first applications based on Berlin datasets are now available via different online application stores.
List of categories: