
Coincidence?

![]() This post was written by Hal Hinderliter, as part of Practitioner Perspectives: Developing, Adapting, and Contextualizing the #DLFteach Toolkit, a blog series from DLF’s Digital Library Pedagogy group highlighting the experiences of digital librarians and archivists who utilize the #DLFteach Toolkit and are new to teaching and/or digital tools.
This post was written by Hal Hinderliter, as part of Practitioner Perspectives: Developing, Adapting, and Contextualizing the #DLFteach Toolkit, a blog series from DLF’s Digital Library Pedagogy group highlighting the experiences of digital librarians and archivists who utilize the #DLFteach Toolkit and are new to teaching and/or digital tools.
The Digital Library Pedagogy working group, also known as #DLFteach, is a grassroots community of practice, empowering digital library practitioners to see themselves as teachers and equip teaching librarians to engage learners in how digital library technologies shape our knowledge infrastructure. The group is open to anyone interested in learning about or collaborating on digital library pedagogy. Join our Google Group to get involved.
For this blog post, I’ve opted to provide some background information on the topic of my #DLFteach Toolkit entry: the EPUB (not an acronym) format, used for books and other documents. Librarians, instructors, instructional designers and anyone else who needs to select file formats for content distribution should be aware of what EPUB has to offer!
Electronic books: the fight over formats
The production and circulation of books, journals, and other long-form texts has been radically impacted by the growth of computer-mediated communication. Electronic books (“e-books”) first emerged near a half-century ago as text-only ASCII files, but are now widely available in a multitude of different file formats. Most notably, three competing options have been competing for market dominance: PDF files, KF8 files (for Amazon’s Kindle devices), and the open-source EPUB format. The popularity of handheld Kindle devices has created a devoted fan base for KF8 e-books, but in academia the ubiquitous PDF file remains the most common way to distribute self-contained digital documents. In contrast to these options, a growing movement is urging that libraries and schools eschew Kindles and abandon their reliance on PDFs in favor of the EPUB electronic book format.
The EPUB file format preserves documents as self-contained packages that manage navigation and presentation separately from the document’s reflowable content, allowing users to alter font sizes, typefaces, and color schemes to suit their individual preferences. E-books saved in the EPUB format are compatible with Apple’s iPads and iPhones as well as Sony’s Reader, Barnes & Nobles Nook, and an expansive selection of software applications for desktop, laptop, and tablet computers. Increasingly, that list includes screen reader software such as Voice Dream and VitalSource Bookshelf, meaning that a single file format – EPUB 3 – can be readily accessed by both sighted and visually impaired audiences.
The lineage of EPUB can be traced back to the Digital Audio-based Information System (DAISY), developed in 1994 under the direction of the Swedish Library of Talking Books and Braille. Today, EPUB is an open-source standard that is managed by the International Digital Publishing Forum, part of the W3C. In contrast to the proprietary origins of both PDF and KF8 e-books, modifications to the open EPUB standard have always been subject to public input and debate.
Accessibility in Academia: EPUB versus PDF
Proponents of universal design principles recommend the use of documents that are fully accessible to everyone, including users of assistive technologies, e.g., screen readers and refreshable braille displays. The DTBook format, a precursor to EPUB, was specifically referenced by Rose et al. (2006) in their initial delineation of Universal Design for Learning (UDL) as part of UDL’s requirement for multiple means of presentation. At the time, the assumption was that DTBooks would be distributed only to students who needed accessible texts, with either printed copies or PDF files for sighted learners. Today, however, it is no longer necessary to provide multiple formats, since EPUB 3 (the accessibility community’s preferred replacement for DTBooks) can be used with equal efficacy by all types of students.
In contrast, PDF files can range from completely inaccessible to largely accessible, depending on the amount of effort the publisher expended during the remediation process. PDF files generated from word processing programs (e.g., Microsoft Word) are not accessible by default, but instead require additional tweaks that necessitate the use of Adobe’s Acrobat Pro software (the version of Acrobat that retails for $179 per year). Users of assistive technologies have no recourse but to attempt opening a PDF file before often finding that the document lacks structure (needed for navigation), alt tags, metadata, or other crucial features. Even for sighted learners, PDFs downloaded from their university’s online repository will be difficult to view on smartphones, since PDF’s fixed page dimensions will require endless zooming and scrolling to display each column of text at an adequate font size.
The superior accessibility of EPUB has inspired major publishers to establish academic repositories of articles in EPUB format, e.g., ABC-CLIO, ACLS Humanities, EBSCO E-Books, Proquest’s Ebrary, Elsevier’s ScienceDirect, Taylor & Francis. Many digital-only journals offer their editions as EPUBs. For example, Trude Eikebrokk, editor of Professions & Professionalism, investigated the advantages of publishing in the EPUB format as described in this excerpt from the online journal Code{4}lib:
There are two important reasons why we wanted to replace PDF as our primary e-journal format. PDF is a print format. It will never be the best choice for reading on tablets (e.g. iPad) or smartphones, and it is challenging to read PDF files on e-book readers … We wanted to replace or supplement the PDF format with EPUB to better support digital reading. Our second reason for replacing PDF with EPUB was to alleviate accessibility challenges. PDF is a format that can cause many barriers, especially for users of screen readers (synthetic speech or Braille). For example, Excel tables are converted into images, which makes it impossible for screen readers to access the table content. PDF documents might also lack search and navigation support, due to either security restrictions, a lack of coded structure in text formats, or the use of PDF image formats. This can make it difficult for any reader to use the document effectively and impossible for screen reader users. On the other hand, correct use of XHTML markup and CSS style sheets in an EPUB file will result in search and navigation functionalities, support for text-to-speech/braille and speech recognition technologies. Accessibility is therefore an essential aspect of publishing e-journals: we must consider diverse user perspectives and make universal design a part of the publishing process.
The Future of EPUB
A robust community of accessibility activists, publishers, and e-book developers continues to advance the EPUB specification. The update to EPUB3 added synchronized audio narration, embedded video, MathML equations, HTML5 animations, and Javascript-based interactivity to the format’s existing support for metadata, hyperlinks, embedded fonts, text (saved as XHTML files) and illustrations in both Scalable Vector Graphic (SVG) and pixel-based formats. Next up: the recently announced upgrade to EPUB 3.2, which embraces documents created under the 3.0 standard while improving support for Accessible Rich Internet Applications (ARIA) and other forms of rich media. If you’re ready to join this revolution, have a run through the #DLFteach Toolkit’s EPUB MakerSpace lesson plan!
The post The #DLFteach Toolkit: Recommending EPUBs for Accessibility appeared first on DLF.
2021-04-27T13:00:54+00:00 Gayle HangingTogether: Nederlandse ronde tafel sessie over next generation metadata: Denk groter dan NACO en WorldCat http://feedproxy.google.com/~r/Hangingtogetherorg/~3/n-ABc9qABiA/Met dank aan Ellen Hartman, OCLC, voor het vertalen van de oorspronkelijke Engelstalige blogpost.
Op 8 maart 2021 werd een Nederlandse ronde tafel discussie georganiseerd als onderdeel van de OCLC Research Discussieserie over Next Generation metadata.
Bibliothecarissen, met achtergronden in metadata, bibliotheeksystemen, de nationale bibliografie en back-office processen, namen deel aan deze sessie. Hierbij werd een mooie variatie aan academische en erfgoed instellingen in Nederland en België vertegenwoordigd. De deelnemers waren geëngageerd, eerlijk en leverden met hun kennis en inzicht constructieve bijdragen aan een prettige uitwisseling van kennis.
 Kaart van next-gen metadata initiatieven (Nederlandse sessie)
Kaart van next-gen metadata initiatieven (Nederlandse sessie)Net als in de andere ronde tafel sessies werden de deelnemers gevraagd om in kaart te helpen brengen wat voor next generation metadata initiatieven er in Nederland en België worden ontplooid. De kaart die daarmee werd gevuld laat zien dat in deze regio een sterke vertegenwoordiging is van bibliografische en erfgoed projecten (zie de linker helft van de matrix). Verschillende next-generation metadata projecten van de Koninklijke Bibliotheek Nederland werden omschreven, zoals:
De Digitale Erfgoed Referentie Architectuur (DERA) is ontwikkeld als onderdeel van een nationale strategie voor digitaal erfgoed in Nederland. Het is een framework voor het beheren en publiceren van erfgoed informatie als linked open data (LOD), op basis van overeengekomen conventies en afspraken. Het van Gogh Worldwide platform is een voorbeeld van de applicatie van DERA, waar metadata gerelateerd aan de kunstwerken van van Gogh, die in bezit zijn van Nederlandse erfgoed instellingen en in privé bezit worden geaggregeerd.
Een noemenswaardig in kaart gebracht initiatief op het gebied van Research Informatie Management (RIM) en Scholarly Communications was de Nederlandse Open Knowledge Base. Een in het afgelopen jaar opgestart initiatief binnen de context van de deal tussen Elsevier en VSNU, NFU en NWO om gezamenlijk open science services te ontwikkelen op basis van RIM systemen, Elsevier databases, analytics oplossingen en de databases van de Nederlandse onderzoeksinstellingen. De Open Knowledge Base zal nieuwe applicaties kunnen voeden met informatie, zoals een dashboard voor het monitoren van de sustainable development goals van de universiteiten. Het uitgangspunt van de Knowledge Base is het significant kunnen verbeteren van de analyse van de impact van research.
Ondanks dat er tijdens de sessie innovatieve projecten in kaart werden gebracht, werd er net als in sommige andere sessies, onduidelijkheid gevoeld over hoe we nu verder door kunnen ontwikkelen. Ook was er sprake van enig ongeduld met de snelheid van de transitie naar next generation metadata. Sommige bibliotheken waren gefrustreerd over het gebrek aan tools binnen de huidige generatie systemen om deze transitie te versnellen. Zoals de integratie van Persistant Identifiers (PID), lokale authorities of links met externe bronnen. Meerdere tools moeten gebruiken voor een workflow voelt als een stap terug in plaats van vooruit.
Buiten praktische belemmeringen werd de discussie vooral gedomineerd door de vraag wat ons tegenhoudt in deze ontwikkeling. Met zoveel bibliografische data die al als LOD gepubliceerd wordt, wat is er dan verder nodig om deze data te linken? Zouden we niet op zoek moeten naar partners om samen een kennis-ecosysteem te ontwikkelen?
Een deelnemer gaf aan dat bibliotheken voorzichtig of terughoudend zijn met de databronnen waarmee ze willen linken. Authority files zijn betrouwbare bronnen, waarvoor er nog geen gelijkwaardige alternatieven bestaan in het zich nog ontwikkelende linked data ecosysteem. Het gebrek aan conventies voor de betrouwbaarheid is misschien een reden waarom bibliotheken misschien wat terughoudend zijn in het aangaan van linked data partnerschappen of terug deinzen voor het vertrouwen op externe data, zelfs van gevestigde bronnen als Wikidata. Want, het linken naar een databron is een indicatie van vertrouwen en een erkenning van de datakwaliteit.
Het gesprek ging vervolgens verder over linked datamodellen. Welke data creëer je zelf? Hoe geef je je data vorm en link je met andere data? Sommige deelnemers gaven aan dat er nog steeds een gebrek aan afspraken en duidelijkheid is over concepten zoals een “werk”. Anderen gaven aan dat het vormgeven van concepten precies is waar linked data om draait en dat meerdere onthologieën naast elkaar kunnen bestaan. In andere woorden, het is misschien niet nodig om de naamgeving in harde standaarden te vatten.
“Er is geen uniek semantisch model. Wanneer je verwijst naar gegevens die al door anderen zijn gedefinieerd, geef je de controle over dat stukje informatie op, en dat kan een mentale barrière zijn tegen het op de juiste manier werken met linked data. Het is veel veiliger om alle data in je eigen silo op te slaan en te beheren. Maar op het moment dat je dat los kunt laten, kan de wereld natuurlijk veel rijker worden dan je in je eentje ooit kunt bereiken.”
Het gesprek ging verder met een discussie over wat we kunnen doen om bibliotheekmedewerkers die catalogiseren te trainen. Een van de deelnemers vond dat het handig zou zijn om te beginnen met ze te leren te denken in linked dataconcepten en om te oefenen met het opbouwen van een knowledge graph en het experimenteren met het bouwen van verschillende structuren. Net als dat een kind dat doet door met LEGO te spelen. De deelnemers waren het erover eens dat we op dit moment nog te weinig kennis hebben van de mogelijkheden en de consequenties van het gebruik van linked data.
“We moeten leren onszelf te zien als uitgevers van metadata, zodat anderen het kunnen vinden – maar we hebben geen idee wie de anderen zijn, we moeten zelfs groter denken dan de NACO van de Library of Congress of WorldCat. We hebben het niet langer over de records die we maken, maar over stukjes records die uniek zijn, want veel komt al van elders. We moeten ons dit realiseren en onszelf afvragen: wat is onze rol in het grotere geheel? Dit is erg moeilijk om te doen!”
De deelnemers gaven aan dat het erg belangrijk was om deze discussie binnen hun bibliotheek op gang te brengen. Maar hoe doe je dat precies? Het is een groot onderwerp en het zou mooi zijn als daar vanuit het management ook aandacht voor is.
Een leidinggevende binnen de deelnemersgroep reageerde hierop en gaf aan:
“Het valt me op dat de hoeveelheid bibliotheken die hier nog echt mee te maken hebben kleiner wordt. (…) [In mijn bibliotheek] produceren we nauwelijks zelf nog metadata. (…) Als we kijken naar wat we zelf nog produceren is dat bijvoorbeeld nog het beschrijven van foto’s van een studentenvereniging, eigenlijk niets dus. Metadata is eigenlijk alleen nog een onderwerp voor een kleine groep specialisten.”
Hoe provocerend deze observatie ook was, dit weerspiegelt wel een realiteit die we moeten erkennen en tegelijkertijd in perspectief moeten plaatsen. Daar was helaas geen tijd voor, want de sessie liep ten einde. Het was zeker een gesprek waar we nog een tijd hadden kunnen doorpraten!
In maart 2021 hield OCLC Research een discussiereeks gericht op twee rapporten:
De rondetafelgesprekken werden gehouden in verschillende Europese talen en de deelnemers konden hun eigen ervaringen delen, een beter begrip krijgen van het onderwerp en kregen handvatten om vol vertrouwen plannen te maken voor de toekomst. .
De plenaire openingssessie opende de vloer voor discussie en verkenning en introduceerde het thema en de bijbehorende onderwerpen. Samenvattingen van alle rondetafelgesprekken worden gepubliceerd op de OCLC Research-blog Hanging Together.
Op de afsluitende plenaire vergadering op 13 april werden de verschillende rondetafelgesprekken samengevat.
The post Nederlandse ronde tafel sessie over next generation metadata: Denk groter dan NACO en WorldCat appeared first on Hanging Together.

On Saturday 6th March 2021, the eleventh Open Data Day took place with people around the world organising over 300 events to celebrate, promote and spread the use of open data.
Thanks to the generous support of this year’s mini-grant funders –Microsoft, UK Foreign, Commonwealth and Development Office, Mapbox, Global Facility for Disaster Reduction and Recovery, Latin American Open Data Initiative, Open Contracting Partnership and Datopian – the Open Knowledge Foundation offered more than 60 mini-grants to help organisations run online or in-person events for Open Data Day.
We captured some of the great conversations across Asia/the Pacific, Europe/Middle East/Africa and the Americas using Twitter Moments.
Below you can discover all the organisations supported by this year’s scheme as well as seeing photos/videos and reading their reports to help you find out how the events went, what lessons they learned and why they love Open Data Day:
Thanks to everyone who organised or took part in these celebrations and see you next year for Open Data Day 2022!
Need more information?
If you have any questions, you can reach out to the Open Knowledge Foundation’s Open Data Day team by emailing opendataday@okfn.org or on Twitter via @OKFN.
2021-04-23T11:04:55+00:00 Stephen Abbott Pugh Digital Library Federation: The #DLFteach Toolkit: Participatory Mapping In a Pandemic https://www.diglib.org/the-dlfteach-toolkit-participatory-mapping-in-a-pandemic/![]() This post was written by Jeanine Finn (Claremont Colleges Library), as part of Practitioner Perspectives: Developing, Adapting, and Contextualizing the #DLFteach Toolkit, a blog series from DLF’s Digital Library Pedagogy group highlighting the experiences of digital librarians and archivists who utilize the #DLFteach Toolkit and are new to teaching and/or digital tools.
This post was written by Jeanine Finn (Claremont Colleges Library), as part of Practitioner Perspectives: Developing, Adapting, and Contextualizing the #DLFteach Toolkit, a blog series from DLF’s Digital Library Pedagogy group highlighting the experiences of digital librarians and archivists who utilize the #DLFteach Toolkit and are new to teaching and/or digital tools.
The Digital Library Pedagogy working group, also known as #DLFteach, is a grassroots community of practice, empowering digital library practitioners to see themselves as teachers and equip teaching librarians to engage learners in how digital library technologies shape our knowledge infrastructure. The group is open to anyone interested in learning about or collaborating on digital library pedagogy. Join our Google Group to get involved.
See the original lesson plan in the #DLFteach Toolkit.
Our original activity was designed around using a live GoogleSheet in coordination with ArcGIS Online to collaboratively map historic locations for an in-class lesson to introduce students to geospatial analysis concepts. In our example, a history instructor had identified a list of cholera outbreaks with place names from 18th-century colonial reports.
In the original activity, students were co-located in a library classroom, reviewing the historic cholera data in groups. A Google Sheet was created and shared with everyone in the class for students to enter “tidied” data from the historic texts collaboratively. The students then worked with a live link from Google Sheets, allowing the outbreak locations to be served directly to the ArcGIS Online map. It was successful and a useful tool for encouraging engagement and for getting familiar with GIS.
Then COVID-19 in 2020 arrived. Instead of a centuries-distant disease outbreak, students learning digital mapping this past year were thrust into socially-distant instructional settings driven by a contemporary pandemic that radically altered their modes of learning. The collaborative affordances of tools like ArcGIS Online were pressed into service to help students collaborate effectively and meaningfully in real-time while learning from home.
As an example, one geology professor at Pomona College encouraged her students to explore the geology of their local environment. Building on shared readings and lectures on geologic history and rock formations, students were encouraged to research the history of the land around them, and include photographs, observations, and other details to enrich the ArcGIS StoryMap. The final map included photographs and geology facts from students’ home locations around the world.
 Header for Geology class group StoryMap at Pomona College, Fall 2020
Header for Geology class group StoryMap at Pomona College, Fall 2020
A key feature of the ArcGIS StoryMap platform that appealed to the instructor was the ability for the students to work collaboratively on the platform itself — not across shared files on folders on Box, GSuite, the LMS, etc. While this functioned reasonably well, there were several roadblocks to effective collaboration that we encountered along the way. Most of the challenges related to permissions settings related to ArcGIS Online administration, as the “shared update” features are not set as default permissions. Other challenges included file size limitations for images the students wished to upload, the inability of more than one user to edit the same file simultaneously, and potential security issues (including firewalls) in nations with more restrictive internet laws.
Reflecting on these uses of StoryMaps over this past semester, we encourage instructors and library staff interested in to:
Resources:
Participatory Mapping with Google Forms, Google Sheets, and ArcGIS Online (Esri community education blog): https://community.esri.com/t5/education-blog/participatory-mapping-with-google-forms-google-sheets-and-arcgis/ba-p/883782
Optimize group settings to share stories like never before (Esri ArcGIS blog): https://www.esri.com/arcgis-blog/products/story-maps/constituent-engagement/optimize-group-settings-to-share-stories-like-never-before/
Teach with Story Maps: Announcing the Story Maps Curriculum Portal (University of Minnesota, U-Spatial: https://research.umn.edu/units/uspatial/news/teach-story-maps-announcing-story-maps-curriculum-portal
Getting Started with ArcGIS StoryMaps (Esri): https://storymaps.arcgis.com/stories/cea22a609a1d4cccb8d54c650b595bc4
VI Conclusion recommendations
Gather materials ahead of time. Photographs from digital archives, maps
There may be data cleaning issues.
The post The #DLFteach Toolkit: Participatory Mapping In a Pandemic appeared first on DLF.
2021-04-22T19:11:26+00:00 Gayle David Rosenthal: Dogecoin Disrupts Bitcoin! https://blog.dshr.org/2021/04/dogecoin-disrupts-bitcoin.html Two topics I've posted about recently, Elon Musk's cult and the illusory "prices" of cryptocurrencies, just intersected in spectacular fashion. On April 14 the Bitcoin "price" peaked at $63.4K. Early on April 15, the Musk cult saw this tweet from their prophet. Immediately, the Dogecoin "price" took off like a Falcon 9.
Two topics I've posted about recently, Elon Musk's cult and the illusory "prices" of cryptocurrencies, just intersected in spectacular fashion. On April 14 the Bitcoin "price" peaked at $63.4K. Early on April 15, the Musk cult saw this tweet from their prophet. Immediately, the Dogecoin "price" took off like a Falcon 9.Dogecoin — the crypto token that was started as a joke and that is the favourite of Elon Musk — is having a bit of a moment. And when we say a bit of a moment, we mean that it is on a lunar trajectory (in crypto talk: it is going to da moon).The headlines tell the story — Timothy B. Lee's Dogecoin has risen 400 percent in the last week because why not and Joanna Ossinger's Dogecoin Rips in Meme-Fueled Frenzy on Pot-Smoking Holiday.
At the time of writing this, it is up over 200 per cent in the past 24 hours — more than tripling in value (for those of you who need help on percentages, it is Friday afternoon after all). Over the past week it’s up more than 550 per cent (almost seven times higher!).
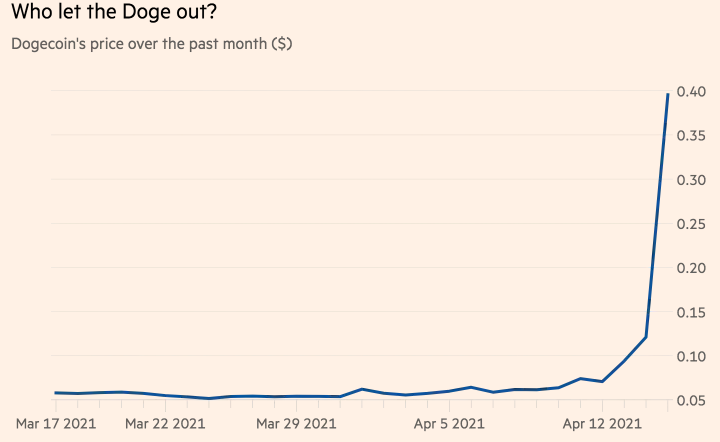 The Dogecoin "price" graph Kelly posted was almost vertical. The same day, Peter Schiff, the notorious gold-bug, tweeted:
The Dogecoin "price" graph Kelly posted was almost vertical. The same day, Peter Schiff, the notorious gold-bug, tweeted:So far in 2021 #Bitcoin has lost 97% of its value verses #Dogecoin. The market has spoken. Dogecoin is eating Bitcoin. All the Bitcoin pumpers who claim Bitcoin is better than gold because its price has risen more than gold's must now concede that Dogecoin is better than Bitcoin.Below the fold I look back at this revolution in crypto-land.
Bitcoin’s hashrate dropped 25% from all-time highs after an accident in the Xinjiang region’s mining industry caused flooding and a gas explosion, leading to 12 deaths with 21 workers trapped since.The drop in the hash rate had the obvious effects. David Gerard reports:
...
The leading Bitcoin mining data centers in the region have closed operations to comply with the fire and safety inspections.
The Chinese central authority is conducting site inspections “on individual mining operations and related local government agencies,” tweeted Dovey Wan, partner at Primitive Crypto.
...
The accident has reignited the centralization problems arising from China’s dominance of the Bitcoin mining sector, despite global expansion efforts.
The Bitcoin hash rate dropped from 220 exahashes per second to 165 EH/s. The rate of new blocks slowed. The Bitcoin mempool — the backlog of transactions waiting to be processed — has filled. Transaction fees peaked at just over $50 average on 18 April.The average BTC transaction fee is now just short of $60, with a median fee over $26! The BTC blockchain did around 350K transactions on April 15, but on April 16 it could only manage 190K.
Dogecoin’s rise is a classic example of greater fool theory at play, Dogecoin investors are basically betting they’ll be able to cash out by selling to the next person wanting to invest. People are buying the cryptocurrency, not because they think it has any meaningful value, but because they hope others will pile in, push the price up and then they can sell off and make a quick buck.Kelly also quotes Khadim Shubber explaining that this is all just entertainment:
But when everyone is doing this, the bubble eventually has to burst and you’re going to be left short-changed if you don’t get out in time. And it’s almost impossible to say when that’s going to happen.
Bitcoin, and cryptocurrencies in general, are not directly analogous to the fairly mundane practice of buying a Lottery ticket, but this part of its appeal is often ignored in favour of more intellectual or high-brow explanations.Note the importance of volatility. In a must-read interview that New York Magazine entitled BidenBucks Is Beeple Is Bitcoin Prof. George Galloway also stressed the importance of volatility:
It has all the hallmarks of a fun game, played out across the planet with few barriers to entry and all the joy and pain that usually accompanies gambling.
There’s a single, addictive reward system: the price. The volatility of cryptocurrencies is often highlighted as a failing, but in fact it’s a key part of its appeal. Where’s the fun in an asset whose price snoozes along a predictable path?
The rollercoaster rise and fall and rise again of the crypto world means that it’s never boring. If it’s down one day (and boy was it down yesterday) well, maybe the next day it’ll be up again.
Young people want volatility. If you have assets and you’re already rich, you want to take volatility down. You want things to stay the way they are. But young people are willing to take risks because they can afford to lose everything. For the opportunity to double their money, they will risk losing everything. Imagine a person who has the least to lose: He’s in solitary confinement in a supermax-security prison. That person wants maximum volatility. He prays for such volatility, that there’s a revolution and they open the prison.This all reinforces my skepticism about the "price" and "market cap" of cryptocurrencies. 2021-04-22T16:00:00+00:00 David. (noreply@blogger.com) David Rosenthal: What Is The Point? https://blog.dshr.org/2021/04/what-is-point.html During a discussion of NFTs, Larry Masinter pointed me to his 2012 proposal The 'tdb' and 'duri' URI schemes, based on dated URIs. The proposal's abstract reads:
People under the age of 40 are fed up. They have less than half of the economic security, as measured by the ratio of wealth to income, that their parents did at their age. Their share of overall wealth has crashed. A lot of them are bored. A lot of them have some stimulus money in their pocket. And in the case of GameStop, they did what’s kind of a mob short squeeze.
...
I see crypto as a mini-revolution, just like GameStop. The central banks and governments are all conspiring to create more money to keep the shareholder class wealthy. Young people think, That’s not good for me, so I’m going to exit the ecosystem and I’m going to create my own currency.
This document defines two URI schemes. The first, 'duri' (standingAs far as I can tell, this proposal went nowhere, but it raises a question that is also raised by NFTs. What is the point of a link that is unlikely to continue to resolve to the expected content? Below the fold I explore this question.
for "dated URI"), identifies a resource as of a particular time.
This allows explicit reference to the "time of retrieval", similar to
the way in which bibliographic references containing URIs are often
written.
The second scheme, 'tdb' ( standing for "Thing Described By"),
provides a way of minting URIs for anything that can be described, by
the means of identifying a description as of a particular time.
These schemes were posited as "thought experiments", and therefore
this document is designated as Experimental.
There are many URIs which are, unfortunately, not particularlyPersonalization, advertisements, geolocation, watermarks, all make it very unlikely that either several clients accessing the same URI at the same time, or a single client accessing the same URI at different times, would see the same content.
"uniform", in the sense that two clients can observe completely
different content for the same resource, at exactly the same time.
There are no direct resolution servers or processes for 'duri' orBut the duri: URI doesn't provide the information needed to resolve to the "cached or archived" content. The Internet Archive's Wayback Machine uses URIs which, instead of the prefix duri:[datetime]: have the prefix https://web.archive.org/web/[datetime]/. This is more useful, both because browsers will actually resolve these URIs, and because they resolve to a service devoted to delivering the content of the URI at the specified time.
'tdb' URIs. However, a 'duri' URI might be "resolvable" in the sense
that a resource that was accessed at a point in time might have the
result of that access cached or archived in an Internet archive
service. See, for example, the "Internet Archive" project
 Photo by Bálint Szabó on Unsplash
Photo by Bálint Szabó on UnsplashAs the COVID pandemic grinds on, vaccinations are top of mind. A recent article published in JAMA Network Open examined whether vaccination clinical trials over the last decade adequately represented various demographic groups in their studies. According to the authors, the results suggested they did not: “among US-based vaccine clinical trials, members of racial/ethnic minority groups and older adults were underrepresented, whereas female adults were overrepresented.” The authors concluded that “diversity enrollment targets should be included for all vaccine trials targeting epidemiologically important infections.”
 Dr. Tiffany Grant
Dr. Tiffany GrantMy colleague Rebecca Bryant and I recently enjoyed an interesting and thought-provoking conversation with Dr. Tiffany Grant, Assistant Director for Research and Informatics with the University of Cincinnati Libraries (an OCLC Research Library Partnership member) on the topic of bias in research data. Dr. Grant neatly summed up the issue by observing that data collected should be inclusive of all the groups who are impacted by outcomes. As the JAMA article illustrates, that is clearly not always the case – and the consequences can be significant for decision- and policy-making in critical areas like health care.
The issue of bias in research data has been acknowledged for some time; for example, the launch of the Human Genome Project in the late 1990s/early 2000s helped raise awareness of the problem, as did observed differences in health care outcomes across demographic groups. And efforts are underway to help remedy some of the gaps. One initiative, the US National Institutes of Health’s All of Us Research Program, aims to build a database of health data collected from a diverse cohort of at least one million participants. The rationale for the project is clearly laid out: “To develop individualized plans for disease prevention and treatment, researchers need more data about the differences that make each of us unique. Having a diverse group of participants can lead to important breakthroughs. These discoveries may help make health care better for everyone.”
Extrapolation of findings observed in one group to all other groups often leads to poor inferences, and researchers should take this into account when designing data collection strategies. The peer review process should act as a filter for identifying research studies that overlook this point in their design – but how well is it working? As in many other aspects of our work and social lives, unconscious bias may play a role here: lack of awareness of the problem on the part of reviewers means that studies with flawed research designs may slip through.
And that leads us to what Dr. Grant believes is the principal remedy for the problem of bias in research data: education. Researchers need training that helps them recognize potential sources of bias in data collection, as well as understand the implications of bias for interpretation and generalization of their findings. The first step in solving a problem is to recognize that there is a problem. Some disciplines are further along than others in addressing bias in research data, but in Dr. Grant’s view, there is still ample scope for raising awareness across campus about this topic.
Academic libraries can help with this, by providing workshops and training programs, and gathering relevant information resources. At the University of Cincinnati, librarians are often embedded in research teams, providing an excellent opportunity to share their expertise on this issue. Raising awareness about bias in research data is also an opportunity to partner with other campus units, such as the office of research, colleges/schools, and research institutes (for more information on how to develop and sustain cross-campus partnerships around research support services see our recent OCLC Research report on social interoperability).
Many institutions are currently implementing Equality, Diversity, and Inclusion (EDI) training, and modules addressing bias in research data might be introduced as part of EDI curricula for researchers. This could also be an area of focus for professional development programs supporting doctoral, postdoctoral, and other early-career researchers. It seems that many EDI initiatives focus on issues related to personal interactions or recruiting more members of underrepresented groups into the field. For researchers, it may be useful to supplement this training with additional programs that focus on EDI issues as they specifically relate to the responsible conduct of research. In other words, how do EDI-related issues manifest in the research process, and how can researchers effectively address them? A great example is the training offered by We All Count, a project aimed at increasing equity in data science.
Funders can also contribute toward mitigating bias in research data, by issuing research design guidelines on inclusion of underrepresented groups, and by establishing criteria for scoring grant proposals on the basis of how well these guidelines are addressed. The big “carrots and sticks” wielded by funders are a powerful tool for both raising awareness and shifting behaviors.
Bias in research data extends to bias in research data management (RDM). Situations where access to and ability to use archived data sets is not equitable is another form of bias. While it is good to mandate that data sets be archived under “open” conditions, as many funders already do, the spirit of the mandate is compromised if the data sets are put into systems that are not accessible and usable to everyone. It is important to recognize that the risk of introducing bias into research data exists throughout the research lifecycle, including curation activities such as data storage, description, and preservation.
Our conversation focused on bias in research data in STEM fields – particularly medicine – but the issue also deserves attention in the context of the social sciences, as well as the arts and humanities. Our summary here highlights just a sample of the topics worthy of discussion in this area, with much to unpack in each one. We are grateful to Dr. Grant for starting a conversation with us on this important issue and look forward to continuing it in the future as part of our ongoing work on RDM and other forms of research support services.
Like so many other organizations, OCLC is reflecting on equity, diversity, and inclusion, as well as taking action. Check out an overview of that work, and explore efforts being undertaken in OCLC’s Membership and Research Division. Thanks to Tiffany Grant, Rebecca Bryant, and Merrilee Proffitt for providing helpful suggestions that improved this post!
The post Recognizing bias in research data – and research data management appeared first on Hanging Together.
Learn how AI-powered recommenders put the right products and content in front of your customers, with just the right amount of human touch.
The post Enhance Product Discovery with AI-Powered Recommenders appeared first on Lucidworks.
2021-04-21T15:35:11+00:00 Andy Wibbels Tara Robertson: Distributing DEI Work Across the Organization https://tararobertson.ca/2021/distributing-dei-work-across-the-organization/I enjoyed being a guest on Seed&Spark‘s first monthly office hours session where Stefanie Monge, Lara McLeod and I talked about distributing diversity, equity and inclusion work across organizations.
The post Distributing DEI Work Across the Organization appeared first on Tara Robertson Consulting.
2021-04-20T17:17:50+00:00 Tara Robertson Terry Reese: Thoughts on NACOs proposed process on updating CJK records https://blog.reeset.net/archives/2967I would like to take a few minutes and share my thoughts about an updated best practice recently posted by the PCC and NACO related to an update on CJK records. The update is found here: https://www.loc.gov/aba/pcc/naco/CJK/CJK-Best-Practice-NCR.docx. I’m not certain if this is active or a simply a proposal, but I’ve been having a number of private discussions with members at the Library of Congress and the PCC as I’ve been trying to understand the genesis for this policy change. I personally believe that formally adopting a policy like this would be exceptionally problematic, and I wanted to flesh out my thoughts on why and some potential better options that could fix the issue that this problem is attempting to solve.
But first, I owe some folks an apology. In chatting with some folks at LC (because, let’s be clear, this proposal was created specifically because there are local, limiting practices at LC that artificially are complicating this work) – it came to my attention that the individuals that spent a good deal of time considering and creating this proposal have received some unfair criticism – and I think I bare a lot of responsibility for that. I have done work creating best practices and standards and its thankless, difficult work. Because of that, in cases where I disagree with a particular best practice, my preference has been to address those privately and attempt to understand and share my issues with a set of practices. This is what I have been doing related to this work. However, on the MarcEdit list (a private list), when a request was made related to a feature request in MarcEdit to support this work – I was less thoughtful in my response as the proposed change could fundamentally undo almost a decade of work as I have dealt with thousands of libraries stymied by these kinds of best practices that have significant unintended consequences. My regret is that I’ve been told that my thoughts shared on the MarcEdit list, have been used by others in more public spaces to take this committee’s work to task. This is unfortunate and disappointing, and something I should have been more thoughtful of in my responses on the MarcEdit list. Especially, given that every member of that committee is doing this work as a service to the community. I know I forget that sometimes. So, to the folks that did this work – I’ve not followed (or seen) any feedback you may have received, but in as much that I’m sure I played a part in any push back you may have received, I’m sorry.
If you look at the proposal, I think that the writers do a good job identifying the issue. Essentially, this issue is unique to authority records. At present, NACO still requires that records created within the program only utilize UTF8 characters that fall within the MARC-8 repertoire. OCLC, the pipeline for creating these records, enforces this rule by invalidating records with UTF8 characters outside the MARC8 range. The proposal seeks to address this by encouraging the use of NRC (Numeric Character Reference) data in UTF8 records, to work around these normalization issues.
So, in a nutshell, that is the problem, and that is the proposed solution. But before we move on, let’s talk a little bit about how we got here. This problem currently exists because of, what I believe to be, an extremely narrow and unproductive read of what MARC8 repertoire actually means. For those not in Libraries, MARC8 is essentially a made-up character encoding, used only in libraries, that has so outlived its usefulness. Modern systems have largely stopped supporting it outside of legacy ingest workflows. The issue is that for every academic library or national library that has transitioned to UTF8, hundreds of small libraries or organizations around the world have not. MARC8 continues to exist because the infrastructure that supports these smaller libraries is built around it.
But again, I think it is worth thinking about today, what actually is the MARC8 repertoire. Previously, this had been a hard set of defined values. But really, that changed in 2004ish when LC updated guidance and introduced the concept of NRCs to preserve lossless data transfer between systems that were fully UTF8 compliant and older MARC8 systems. NRCs in MARC8 were workable, because it left local systems the ability to handle (or not handle) the data as it seen fit and finally provided an avenue for the Library community as a whole to move on from the limitations MARC8 was imposing on systems. It allowed for the facilitation of data into non-MARC formats that were UTF8 compliant and provided a pathway to allow data from other metadata formats, the ability to reuse that data in MARC records. I would argue that today, the MARC8 repertoire includes NRC notation – and to assume or pretend otherwise, is shortsighted and revisionist.
But why is all of this important. Well, it is at the heart of the problem that we find ourselves in. For authority data, the Library of Congress appears to have adopted this very narrow view of what MARC8 means (against their own stated recommendations) and as a result, NACO and OCLC place artificial limits on the pipeline. There are lots of reasons why LC does this, I recognize they are moving slowly because any changes that they make are often met with some level of resistance from members of our community – but in this case, this paralysis is causing more harm to the community than good.
So, this is the environment that we are working in and the issue this proposal sought to solve. The issue, however, is that the proposal attempts to solve this problem by adopting a MARC8 solution and applying it within UTF8 data – essentially making the case that NRC values can be embedded in UTF8 records to ensure lossless data entry. And while I can see why someone might think that – that assumption is fundamentally incorrect. When LC developed its guidance on NRC notation, this was guidance that was specifically directed in the lossless translation of data to MARC8. UTF8 data has no need for NRC notation. This does not mean that it does not sometimes show up – and as a practical purpose, I’ve spent thousands of hours working with Libraries dealing with the issues this creates in local systems. Aside from the issues this creates in MARC systems around indexing and discovery, it makes data almost impossible to be used outside of that system and in times of migration. In thinking about the implications of this change in the context of MarcEdit, I had the following, specific concerns:
While I very much appreciate the issue that this is attempting to solve, I’ve spent years working with libraries where this kind of practice would introduce a long-term data issue that is very difficult to identify and fix and often shows up unexpectedly when it comes time to migration or share this information with other services, communities, or organizations.
I think that we can address this issue on two fronts. First, I would advise NACO and OCLC to essentially stop limiting data entry to this very limited notion of MARC8 repertoire. In all other contexts, OCLC provides the ability to enter any valid UTF8 data. This current limit within the authority process is artificial and unnecessary. OCLC could easily remove it, and NACO could amend their process to allow record entry to utilize any valid UTF8 character. This would address the problem that this group was attempting to solve for catalogers creating these records.
The second step could take two forms. If LC continues to ignore their own guidance and cleave to an outdated concept of the MARC8 repertoire – OCLC could provide to LC via their pipeline a version of the records where data includes NRC notation for use in LCs own systems. It would mean that I would not recommend using LC as a trusted system for downloading authorities if this was the practice unless I had an internal local process to remove any NRC data found in valid UTF8 records. Essentially, we essentially treat LC’s requirements as a disease and quarantine them and their influence in this process. Of course, what would be more ideal, is LC making the decision to accept UTF8 data without restrictions and rely on applicable guidance and MARC21 best practice by supporting UTF8 data fully, and for those still needing MARC8 data – providing that data using the lossless process of NRCs (per their own recommendations).
Ultimately, this proposal is a recognition that the current NACO rules and process is broken and broken in a way that it is actively undermining other work in the PCC around linked data development. And while I very much appreciate the thoughtful work that went into the consideration of a different approach, I think the unintended side affects would cause more long-term damage that any short-term gains. Ultimately, what we need is for the principles to rethink why these limitations are in place, and, honestly, really consider ways that we start to deemphasize the role LC plays as a standard holder if in that role, LC’s presence continues to be an impediment for moving libraries forward.
2021-04-20T16:56:13+00:00 reeset Lucidworks: How to Deliver Impactful Digital Commerce Experiences https://lucidworks.com/post/deliver-relevant-digital-commerce-experiences/Acquia and Lucidworks share tips for how to deliver meaningful and relevant digital commerce experiences that create customer connections.
The post How to Deliver Impactful Digital Commerce Experiences appeared first on Lucidworks.
2021-04-20T16:32:04+00:00 Jenny Gomez HangingTogether: Accomplishments and priorities for the OCLC Research Library Partnership http://feedproxy.google.com/~r/Hangingtogetherorg/~3/sV5OSw6YBAI/With 2021 well underway, the OCLC Research Library Partnership is as active as ever. We are heartened by the positive feedback and engagement our Partners have provided in response to our programming and research directions. Thank you to those who have shared your stories of success and challenge; listening to your voices is what guides us and drives us forward. We warmly welcome the University of Notre Dame, University of Waterloo, and OCAD University into the Partnership and are pleased to see how they have jumped right into engagement with SHARES and other activities.
 Photo by Caleb Chen on Unsplash
Photo by Caleb Chen on UnsplashThe SHARES community has been a source of support and encouragement as resource sharing professionals around the world strive to meet their communities’ information needs during COVID-19. During the last year, Dennis Massie has convened more than 50 SHARES town halls to date to learn how SHARES members are changing practice to adapt to quickly evolving circumstances. Dennis has documented how resource sharing practices have changed.
Inspired by the SHARES community, we are also excited to have launched the OCLC Interlibrary Loan Cost Calculator. For library administrators and funders to evaluate collection sharing services properly, they need access to current cost information, as well as benchmarks against which to measure their own library’s data. The Cost Calculator is a free online tool that has the potential to act as a virtual real-time ILL cost study. Designed in collaboration with resource sharing experts and built by OCLC Research staff, the calculator has been in the hands of beta testers and early adopters since October 2019. A recorded webinar gives a guided tour of what the tool does (and does not do), what information users need to gather, how developers addressed privacy issues, and how individual institutions and the library community can benefit.
A big thanks to our Partners who contributed to the Total Cost of Stewardship: Responsible Collection Building in Archives and Special Collections. This publication addresses the ongoing challenge of descriptive backlogs in archives and special collections by connecting collection development decisions with stewardship responsibilities. The report proposes a Total Cost of Stewardship framework for bringing together these important, interconnected functions. Developed by the RLP’s Collection Building and Operational Impacts Working Group, the Total Cost of Stewardship Framework is a model that considers the value of a potential acquisition and its alignment with institutional mission and goals alongside the cost to acquire, care for, and manage it, the labor and specialized skills required to do that work, and institutional capacity to care for and store collections.
This publication includes a suite of communication and cost estimation tools to help decision makers assess available resources, budgets, and timelines to plan with confidence and set realistic expectations to meet important goals. The report and accompanying resources provide special collections and archives with tools to support their efforts to meet the challenges of contemporary collecting and to ensure they are equitably serving and broadly documenting their communities.
In December, we had a bittersweet moment celebrating Senior Program Officer Karen Smith-Yoshimura’s retirement. As Mercy Procaccini and others take over the role of coordinating the stalwart Metadata Managers Focus Group, we are taking time to refine how this dynamic group works and plans future discussions together to better support their efforts. A synthesis of this group’s discussions from the past six years traces how metadata services are transitioning to the “next generation of metadata.”
The RLP’s commitment to advancing learning and operational support for linked data continues with the January publication of Transforming Metadata into Linked Data to Improve Digital Collection Discoverability: A CONTENTdm Pilot Project. The report details a pilot project that investigated methods for—and the feasibility of—transforming metadata into linked data to improve the discoverability and management of digitized cultural materials and their descriptions. Five institutions partnered with OCLC to collaborate on this linked data project, representing a diverse cross-section of different types of institutions: The Cleveland Public Library The Huntington Library, Art Museum, and Botanical Gardens The Minnesota Digital Library Temple University Libraries University of Miami Libraries.
OCLC has invested in pathbreaking linked data work for over a decade, and it is wonderful to add the publication to this knowledge base.
In the area of research support, Rebecca Bryant developed a robust series of webinars as a follow-on to the 2019–2020 OCLC Research project, Social Interoperability in Research Support. The resulting report, Social Interoperability in Research Support: Cross-campus Partnerships and the University Research Enterprise, synthesizes information about the highly decentralized, complex research support ecosystem at US research institutions. The report additionally offers a conceptual model of campus research support stakeholders and provides recommendations for establishing and stewarding successful cross-campus relationships. The social interoperability webinar series complements this work by offering in-depth case studies and “stakeholder spotlights” from RLP institutions, demonstrating how other campus are eager to collaborate with the library. This is a great example of the type of programming you can find in our Works in Progress Webinar Series.
Our team has been digging into issues of equity, diversity, and inclusion: we’ve developed a “practice group” to help our team be better situated to engaging in difficult conversations around race, and we also have been learning and engaging in conversations about the difficulty of cataloging topics relating to Indigenous peoples in respectful ways.
This work has helped to prepare the way for important new work that I’m pleased to share with you today. OCLC will be working in consultation with Shift Collective on The Andrew W. Mellon-funded convening, Reimagine Descriptive Workflows. The project will bring together a wide range of community stakeholders to interrogate the existing descriptive workflow infrastructure to imagine new workflows that are inclusive, equitable, scalable, and sustainable. We are following an approach developed in other work we have carried out, such as the Research and Learning Agenda for Archives, Special, and Distinctive Collections in Research Libraries, and more recently, in Responsible Operations: Data Science, Machine Learning, and AI in Libraries. In that vein, we will host a virtual convening later this year to inform a Community Agenda publication.
Reimagine Descriptive Workflows is the next stage of a journey that we’ve been on for some time, informed by numerous webinars, surveys, and individual conversations. I am very grateful to team members and the RLP community for their contributions and guidance. We are truly “learning together.”
If you are at an OCLC RLP affiliated institution and would like to learn more about how to get the most out of your RLP affiliation, please contact your staff liaison (or anyone on our energetic team) and we be happy to set up a virtual orientation or refresher on our programs and opportunities for active learning.
It is with deep gratitude that I offer my thanks to to our Partners for their investment in the Research Library Partnership. We are committed to offering our very best to serve your research and learning needs.
The post Accomplishments and priorities for the OCLC Research Library Partnership appeared first on Hanging Together.
This week, five shortlisted teams took part in the final stage of the Net Zero Challenge – a global competition to identify, promote and support innovative, practical and scalable uses of open data that advance climate action.
The five teams presented their three-minute project pitches to the Net Zero Challenge Panel of Experts, and a live audience. Each pitch was followed by a live Q&A.
The winner of the pitch contest will be announced in the next few days.
If you didn’t have the chance to attend the event in person, watch the event here (46.08.min) or see below for links to individual pitches.
A full unedited video of the event is at the bottom of this page.
![]()
Introduction – by James Hamilton, Director of the Net Zero Challenge
Watch video here (4.50min) // Introduction Slide Deck

Pitch 1 – by Matt Sullivan from Snapshot Climate Tool which provides greenhouse gas emission profiles for every local government region (municipality) in Australia.
Watch pitch video here (10.25min) // Snapshot Slide Deck

Pitch 2 – by Saif Shabou from CarbonGeoScales which is a framework for standardising open data for green house gas emissions at multiple geographical scales (built by a team from France).
Watch pitch video here (9.07min) // CarbonGeoScales Slide Deck

Pitch 3 – by Jeremy Dickens. He presents Citizen Science Avian Index for Sustainable Forests a new bio monitoring tool that uses open data on bird observations to provide crucial information on forest ecological conditions (from South Africa).
Watch pitch video here (7.03min) // Avian Index – Slide Deck

Pitch 4 – by Cristian Gregorini from Project Yarquen which is a new API tool and website to organise climate relevant open data for use by civil society organisations, environmental activists, data journalists and people interested in environmental issues (built by a team from Argentina).
Watch pitch video here (8.20min)

Pitch 5 – by Beatriz Pagy from Clima de Eleição which analyses recognition of climate change issues by prospective election candidates in Brazil, enabling voters to make informed decisions about who to vote in to office.
Watch pitch video here (5.37min) // Clima de Eleição – Slide Deck

Concluding remarks – by James Hamilton, Director of the Net Zero Challenge
A full unedited video of the Net Zero Challenge is here (55.28min)
There are many people who collaborated to make this event possible.
We wish to thank both Microsoft and the UK Foreign, Commonwealth & Development Office for their support for the Net Zero Challenge. Thanks also to Open Data Charter and the Open Data & Innovation Team at Transport for New South Wales for their strategic advice during the development of this project. The event would not have been possible without the enthusiastic hard work of the Panel of Experts who will judge the winning entry, and the audience who asked such great questions. Finally – to all the pitch teams. Your projects inspire us and we hope your participation in the Net Zero Challenge has been – and will continue to be – supportive for your work as you use open data to advance climate action.
2021-04-19T09:43:32+00:00 James Hamilton Hugh Rundle: A barbaric yawp https://www.hughrundle.net/a-barbaric-yawp/Over the Easter break I made a little Rust tool for sending toots and/or tweets from a command line. Of course there are dozens of existing tools that enable either of these, but I had a specific use in mind, and also wanted a reasonably small and achievable project to keep learning Rust.
For various reasons I've recently been thinking about the power of "the Unix philosophy", generally summarised as:
- Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams, because that is a universal interface.
My little program takes a text string as input, and sends the same string to the output, the intention being not so much that it would normally be used manually on its own (though it can be) but more that it can "work together" with other programs or scripts. The "one thing" it does (I will leave the question of "well" to other people to judge) is post a tweet and/or toot to social media. It's very much a unidirectional, broadcast tool, not one for having a conversation. In that sense, it's like Whitman's "Barbaric yawp", subject of my favourite scene in Dead Poets Society and a pretty nice description of what social media has become in a decade or so. Calling the program yawp therefore seemed fitting.
yawp takes text from standard input (stdin), publishes that text as a tweet and/or a toot, and then prints it to standard output (stdout). Like I said, it's not particularly complex, and not even all that useful for your daily social media posting needs, but the point is for it to be part of a tool chain. For this reason yawp takes the configuration it needs to interact with the Mastodon and Twitter APIs from environment (ENV) variables, because these are quite easy to set programatically and a fairly "universal interface" for setting and getting values to be used in programs.
Here's a simple example of sending a tweet:
yawp 'Hello, World!' -tWe could also send a toot by piping from the echo program (the - tells yawp to use stdin instead of looking for an argument like it uses above):
echo 'Hello again, World!' | yawp - -mIn bash, you can send the contents of a file to stdin, so we could do this too:
yawp - -mt <message.txtBut really the point is to use yawp to do something like this:
app_that_creates_message | yawp - -mt | do_something_else.sh >> yawping.logAnyway, enjoy firing your barbaric yawps into the cacophony.
“Let’s blog every Friday,” I thought. “It’ll be great. People can see what I’m doing with ML, and it will be a useful practice for me!” And then I went through weeks on end of feeling like I had nothing to report because I was trying approach after approach to this one problem that simply didn’t work, hence not blogging. And finally realized: oh, the process is the thing to talk about…
Hi. I’m Andromeda! I am trying to make a neural net better at recognizing people in archival photos. After running a series of experiments — enough for me to have written 3,804 words of notes — I now have a neural net that is ten times worse at its task. 
And now I have 3,804 words of notes to turn into a blog post (a situation which gets harder every week). So let me catch you up on the outline of the problem:
Step 3: profit, right? Well. Let me also catch you up on some problems along the way:
Archival photos are great because they have metadata, and metadata is like labels, and labels mean you can do supervised learning, right?
Well….
Is he “Du Bois, W. E. B. (William Edward Burghardt), 1868-1963” or “Du Bois, W. E. B. (William Edward Burghardt) 1868-1963” or “Du Bois, W. E. B. (William Edward Burghardt)” or “W.E.B. Du Bois”? I mean, these are all options. People have used a lot of different metadata practices at different institutions and in different times. But I’m going to confuse the poor computer if I imply to it that all these photos of the same person are photos of different people. (I have gone through several attempts to resolve this computationally without needing to do everything by hand, with only modest success.)
What about “Photographs”? That appears in the list of subject labels for lots of things in my data set. “Photographs” is a person, right? I ended up pulling in an entire other ML component here — spaCy, to do some natural language processing to at least guess which lines are probably names, so I can clear the rest of them out of my way. But spaCy only has ~90% accuracy on personal names anyway and, guess what, because everything is terrible, in predictable ways, it has no idea “Kweisi Mfume” is a person.
Is a person who appears in the photo guaranteed to be a person who appears in the photo? Nope.
Is a person who appears in the metadata guaranteed to be a person who appears in the photo? Also nope! Often they’re a photographer or other creator. Sometimes they are the subject of the depicted event, but not themselves in the photo. (spaCy will happily tell you that there’s personal name content in something like “Martin Luther King Day”, but MLK is unlikely to appear in a photo of an MLK day event.)
OK but let’s imagine for the sake of argument that we live in a perfect world where the metadata is exactly what we need — no more, no less — and its formatting is perfectly consistent. 
Here you are, in this perfect world, confronted with a photo that contains two people and has two names. How do you like them apples?
I spent more time than I care to admit trying to figure this out. Can I bootstrap from photos that have one person and one name — identify those, subtract them out of photos of two people, go from there? (Not reliably — there’s a lot of data I never reach that way — and it’s horribly inefficient.)
Can I do something extremely clever with matrix multiplication? Like…once I generate vector space embeddings of all the photos, can I do some sort of like dot-product thing across all of my photos, or big batches of them, and correlate the closest-match photos with overlaps in metadata? Not only is this a process which begs the question — I’d have to do that with the ML system I have not yet optimized for archival photo recognition, thus possibly just baking bad data in — but have I mentioned I have taken exactly one linear algebra class, which I didn’t really grasp, in 1995?
What if I train yet another ML system to do some kind of k-means clustering on the embeddings? This is both a promising approach and some really first-rate yak-shaving, combining all the question-begging concerns of the previous paragraph with all the crystalline clarity of black box ML.
Possibly at this point it would have been faster to tag them all by hand, but that would be admitting defeat. Also I don’t have a research assistant, which, let’s be honest, is the person who would usually be doing this actual work. I do have a 14-year-old and I am strongly considering paying her to do it for me, but to facilitate that I’d have to actually build a web interface and probably learn more about AWS, and the prospect of reading AWS documentation has a bracing way of reminding me of all of the more delightful and engaging elements of my todo list, like calling some people on the actual telephone to sort out however they’ve screwed up some health insurance billing.
Despite all of that, I did actually get all the way through the 5 steps above. I have a truly, spectacularly terrible neural net. Go me! But at a thousand-plus words, perhaps I should leave that story for next week….
2021-04-16T21:08:54+00:00 Andromeda Lucidworks: Tips for Mixed Reality in Retail https://lucidworks.com/post/tips-for-mixed-reality-in-retail/How retailers are turning to virtual reality, augmented reality, and mixed reality applications to recreate the in-store experience from anywhere.
The post Tips for Mixed Reality in Retail appeared first on Lucidworks.
2021-04-16T17:51:10+00:00 Andy Wibbels Erin White: Talk: Using light from the dumpster fire to illuminate a more just digital world https://erinrwhite.com/talk-using-light-from-the-dumpster-fire-to-illuminate-a-more-just-digital-world/This February I gave a lightning talk for the Richmond Design Group. My question: what if we use the light from the dumpster fire of 2020 to see an equitable, just digital world? How can we change our thinking to build the future web we need?
Presentation is embedded here; text of talk is below.
Hi everybody, I’m Erin. Before I get started I want to say thank you to the RVA Design Group organizers. This is hard work and some folks have been doing it for YEARS. Thank you to the organizers of this group for doing this work and for inviting me to speak.
This talk isn’t about 2020. This talk is about the future. But to understand the future, we gotta look back.
Travel with me to 1996. Twenty-five years ago!
I want to transport us back to the mindset of the early web. The fundamental idea of hyperlinks, which we now take for granted, really twisted everyone’s noodles. So much of the promise of the early web was that with broad access to publish in hypertext, the opportunities were limitless. Technologists saw the web as an equalizing space where systems of oppression that exist in the real world wouldn’t matter, and that we’d all be equal and free from prejudice. Nice idea, right?
You don’t need to’ve been around since 1996 to know that’s just not the way things have gone down.
Pictured before you are some of the early web pioneers. Notice a pattern here?
These early visions of the web, including Barlow’s declaration of independence of cyberspace, while inspiring and exciting, were crafted by the same types of folks who wrote the actual declaration of independence: the landed gentry, white men with privilege. Their vision for the web echoed the declaration of independence’s authors’ attempts to describe the world they envisioned. And what followed was the inevitable conflict with reality.
We all now hold these truths to be self-evident:
Profit first: monetization, ads, the funnel, dark patterns
Can we?: Innovation for innovation’s sake
Solutionism: code will save us
Visual design: aesthetics over usability
Lone genius: “hard” skills and rock star coders
Short term thinking: move fast, break stuff
Shipping: new features, forsaking infrastructure
Let’s move forward quickly through the past 25 years or so of the web, of digital design.
All of the web we know today has been shaped in some way by intersecting matrices of domination: colonialism, capitalism, white supremacy, patriarchy. (Thank you, bell hooks.)
The digital worlds where we spend our time – and that we build!! – exist in this way.
This is not an indictment of anyone’s individual work, so please don’t take it personally. What I’m talking about here is the digital milieu where we live our lives.
The funnel drives everything. Folks who work in nonprofits and public entities often tie ourselves in knots to retrofit our use cases in order to use common web tools (google analytics, anyone?)
In chasing innovation we often overlook important infrastructure work, and devalue work — like web accessibility, truly user-centered design, care work, documentation, customer support and even care for ourselves and our teams — that doesn’t drive the bottom line. We frequently write checks for our future selves to cash, knowing damn well that we’ll keep burying ourselves in technical debt. That’s some tough stuff for us to carry with us every day.
we often overlook important infrastructure work, and devalue work — like web accessibility, truly user-centered design, care work, documentation, customer support and even care for ourselves and our teams — that doesn’t drive the bottom line. We frequently write checks for our future selves to cash, knowing damn well that we’ll keep burying ourselves in technical debt. That’s some tough stuff for us to carry with us every day.
The “move fast” mentality has resulted in explosive growth, but at what cost? And in creating urgency where it doesn’t need to exist, focusing on new things rather than repair, the end result is that we’re building a house of cards. And we’re exhausted.
To zoom way out, this is another manifestation of late capitalism. Emphasis on LATE. Because…2020 happened.
Hard times amplify existing inequalities
Cutting corners mortgages our future
Infrastructure is essential
“Colorblind”/color-evasive policy doesn’t cut it
Inclusive design is vital
We have a duty to each other
Technology is only one piece
Together, we rise
The past year has been awful for pretty much everybody.
But what the light from this dumpster fire has illuminated is that things have actually been awful for a lot of people, for a long time. This year has shown us how perilous it is to avoid important infrastructure work and to pursue innovation over access. It’s also shown us that what is sometimes referred to as colorblindness — I use the term color-evasiveness because it is not ableist and it is more accurate — a color-evasive approach that assumes everyone’s needs are the same in fact leaves people out, especially folks who need the most support.
We’ve learned that technology is a crucial tool and that it’s just one thing that keeps us connected to each other as humans.
Finally, we’ve learned that if we work together we can actually make shit happen, despite a world that tells us individual action is meaningless. Like biscuits in a pan, when we connect, we rise together.
Marginalized folks have been saying this shit for years.
More of us than ever see these things now.
And now we can’t, and shouldn’t, unsee it.
Current state:
– Profit first
– Can we?
– Solutionism
– Aesthetics
– “Hard” skills
– Rockstar coders
– Short term thinking
– ShippingFuture state:
– People first: security, privacy, inclusion
– Should we?
– Holistic design
– Accessibility
– Soft skills
– Teams
– Long term thinking
– Sustaining
So let’s talk about the future. I told you this would be a talk about the future.
Like many of y’all I have had a very hard time this year thinking about the future at all. It’s hard to make plans. It’s hard to know what the next few weeks, months, years will look like. And who will be there to see it with us.
But sometimes, when I can think clearly about something besides just making it through every day, I wonder.
What does a people-first digital world look like? Who’s been missing this whole time?
Just because we can do something, does it mean we should?
Will technology actually solve this problem? Are we even defining the problem correctly?
What does it mean to design knowing that even “able-bodied” folks are only temporarily so? And that our products need to be used, by humans, in various contexts and emotional states?
(There are also false binaries here: aesthetics vs. accessibility; abled and disabled; binaries are dangerous!)
How can we nourish our collaborations with each other, with our teams, with our users? And focus on the wisdom of the folks in the room rather than assigning individuals as heroes?
How can we build for maintenance and repair? How do we stop writing checks our future selves to cash – with interest?
Some of this here, I am speaking of as a web user and a web creator. I’ve only ever worked in the public sector. When I talk with folks working in the private sector I always do some amount of translating. At the end of the day, we’re solving many of the same problems.
But what can private-sector workers learn from folks who come from a public-sector organization?
And, as we think about what we build online, how can we also apply that thinking to our real-life communities? What is our role in shaping the public conversation around the use of technologies? I offer a few ideas here, but don’t want them to limit your thinking.
Here’s a thread about public service.

— Dana Chisnell (she / her) (@danachis) February 5, 2021
I don’t have a ton of time left today. I wanted to talk about public service like the very excellent Dana Chisnell here.
Like I said, I’ve worked in the public sector, in higher ed, for a long time. It’s my bread and butter. It’s weird, it’s hard, it’s great.
There’s a lot of work to be done, and it ain’t happening at civic hackathons or from external contractors. The call needs to come from inside the house.
Government should be
– inclusive of all people
– responsive to needs of the people
– effective in its duties & purpose— Dana Chisnell (she / her) (@danachis) February 5, 2021
I want you to consider for a minute how many folks are working in the public sector right now, and how technical expertise — especially in-house expertise — is something that is desperately needed.
Pictured here are the old website and new website for the city of Richmond. I have a whole ‘nother talk about that new Richmond website. I FOIA’d the contracts for this website. There are 112 accessibility errors on the homepage alone. It’s been in development for 3 years and still isn’t in full production.
Bottom line, good government work matters, and it’s hard to find. Important work is put out for the lowest bidder and often external agencies don’t get it right. What would it look like to have that expertise in-house?
We also desperately need lawmakers and citizens who understand technology and ask important questions about ethics and human impact of systems decisions.
Pictured here are some headlines as well as a contract from the City of Richmond. Y’all know we spent $1.5 million on a predictive policing system that will disproportionately harm citizens of color? And that earlier this month, City Council voted to allow Richmond and VCU PD’s to start sharing their data in that system?
The surveillance state abides. Technology facilitates.
I dare say these technologies are designed to bank on the fact that lawmakers don’t know what they’re looking at.
My theory is, in addition to holding deep prejudices, lawmakers are also deeply baffled by technology. The hard questions aren’t being asked, or they’re coming too late, and they’re coming from citizens who have to put themselves in harm’s way to do so.
Technophobia is another harmful element that’s emerged in the past decades. What would a world look like where technology is not a thing to shrug off as un-understandable, but is instead deftly co-designed to meet our needs, rather than licensed to our city for 1.5 million dollars? What if everyone knew that technology is not neutral?
This is some of the future I can see. I hope that it’s sparked new thoughts for you.
Let’s envision a future together. What has the light illuminated for you?
Thank you!
2021-04-16T14:27:12+00:00 erinrwhite David Rosenthal: NFTs and Web Archiving https://blog.dshr.org/2021/04/nfts-and-web-archiving.html One of the earliest observations of the behavior of the Web at scale was "link rot". There were a lot of 404s, broken links. Research showed that the half-life of Web pages was alarmingly short. Even in 1996 this problem was obvious enough for Brewster Kahle to found the Internet Archive to address it. From the Wikipedia entry for Link Rot:A 2003 study found that on the Web, about one link out of every 200 broke each week,[1] suggesting a half-life of 138 weeks. This rate was largely confirmed by a 2016–2017 study of links in Yahoo! Directory (which had stopped updating in 2014 after 21 years of development) that found the half-life of the directory's links to be two years.[2]One might have thought that academic journals were a relatively stable part of the Web, but research showed that their references decayed too, just somewhat less rapidly. A 2013 study found a half-life of 9.3 years. See my 2015 post The Evanescent Web.
http://www.example.com/page.htmlkeep the copy for posterity, and re-publish it at a URL like:
https://web.archive.org/web/19960615083712/http://www.example.com/page.htmlWhat is the difference between the two URLs? The original is controlled by Example.Com, Inc.; they can change or delete it on a whim. The copy is controlled by the Internet Archive, whose mission is to preserve it unchanged "for ever". The original is subject to "link rot", the second is, one hopes, not subject to "link rot". The Wayback Machine's URLs have three components:
 In People's Expensive NFTs Keep Vanishing. This Is Why, Ben Munster reports that:
In People's Expensive NFTs Keep Vanishing. This Is Why, Ben Munster reports that:over the past few months, numerous individuals have complained about their NFTs going “missing,” “disappearing,” or becoming otherwise unavailable on social media. This despite the oft-repeated NFT sales pitch: that NFT artworks are logged immutably, and irreversibly, onto the Ethereum blockchain.So NTFs have the same problem that Web pages do. Isn't the blockchain supposed to make things immortal and immutable?
When NFT’s are used to represent digital files (like GIFs or videos), however, those files usually aren’t stored directly “on-chain” in the token itself. Doing so for any decently sized file could get prohibitively expensive, given the cost of replicating those files across every user on the chain. Instead, most NFTs store the actual content as a simple URI string in their metadata, pointing to an Internet address where the digital thing actually resides.
 NFTs are just links to the content they represent, not the content itself. The Bitcoin blockchain actually does contain some images, such as this ASCII portrait of Len Sassaman and some pornographic images. But the blocks of the Bitcoin blockchain were originally limited to 1MB and are now effectively limited to around 2MB, enough space for small image files. What’s the Maximum Ethereum Block Size? explains:
NFTs are just links to the content they represent, not the content itself. The Bitcoin blockchain actually does contain some images, such as this ASCII portrait of Len Sassaman and some pornographic images. But the blocks of the Bitcoin blockchain were originally limited to 1MB and are now effectively limited to around 2MB, enough space for small image files. What’s the Maximum Ethereum Block Size? explains:Instead of a fixed limit, Ethereum block size is bound by how many units of gas can be spent per block. This limit is known as the block gas limit ... At the time of writing this, miners are currently accepting blocks with an average block gas limit of around 10,000,000 gas. Currently, the average Ethereum block size is anywhere between 20 to 30 kb in size.That's a little out-of-date. Currently the block gas limit is around 12.5M gas per block and the average block is about 45KB. Nowhere near enough space for a $69M JPEG. The NFT for an artwork can only be a link. Most NFTs are ERC-721 tokens, providing the optional Metadata extension:
/// @title ERC-721 Non-Fungible Token Standard, optional metadata extensionThe Metadata JSON Schema specifies an object with three string properties:
/// @dev See https://eips.ethereum.org/EIPS/eip-721
/// Note: the ERC-165 identifier for this interface is 0x5b5e139f.
interface ERC721Metadata /* is ERC721 */ {
/// @notice A descriptive name for a collection of NFTs in this contract
function name() external view returns (string _name);
/// @notice An abbreviated name for NFTs in this contract
function symbol() external view returns (string _symbol);
/// @notice A distinct Uniform Resource Identifier (URI) for a given asset.
/// @dev Throws if `_tokenId` is not a valid NFT. URIs are defined in RFC
/// 3986. The URI may point to a JSON file that conforms to the "ERC721
/// Metadata JSON Schema".
function tokenURI(uint256 _tokenId) external view returns (string);
}
 Caveat emptor — Absent unspecified actions, the purchaser of an NFT is buying a supposedly immutable, non-fungible object that points to a URI pointing to another URI. In practice both are typically URLs. The token provides no assurance that either of these links resolves to content, or that the content they resolve to at any later time is what the purchaser believed at the time of purchase. There is no guarantee that the creator of the NFT had any copyright in, or other rights to, the content to which either of the links resolves at any particular time.
Caveat emptor — Absent unspecified actions, the purchaser of an NFT is buying a supposedly immutable, non-fungible object that points to a URI pointing to another URI. In practice both are typically URLs. The token provides no assurance that either of these links resolves to content, or that the content they resolve to at any later time is what the purchaser believed at the time of purchase. There is no guarantee that the creator of the NFT had any copyright in, or other rights to, the content to which either of the links resolves at any particular time.As opposed to a centrally located server, IPFS is built around a decentralized system[5] of user-operators who hold a portion of the overall data, creating a resilient system of file storage and sharing. Any user in the network can serve a file by its content address, and other peers in the network can find and request that content from any node who has it using a distributed hash table (DHT). In contrast to BitTorrent, IPFS aims to create a single global network. This means that if Alice and Bob publish a block of data with the same hash, the peers downloading the content from Alice will exchange data with the ones downloading it from Bob.[6] IPFS aims to replace protocols used for static webpage delivery by using gateways which are accessible with HTTP.[7] Users may choose not to install an IPFS client on their device and instead use a public gateway.If the purchaser gets both the NFT's metadata and the content to which it refers via IPFS URIs, they can be assured that the data is valid. What do these IPFS URIs look like? The (excellent) IPFS documentation explains:
Note the assumption here that the ipfs.io gateway will be running forever. Note also that only some browsers are capable of accessing IPFS content without using a gateway. Thus the ipfs.io gateway is a single point of failure, although the failure is not complete. In practice NFTs using IPFS URIs are dependent upon the continued existence of Protocol Labs, the organization behind IPFS. The ipfs.io URIs in the NFT metadata are actually URLs; they don't point to IPFS, but to a Web server that accesses IPFS.https://ipfs.io/ipfs/<CID>Browsers that support IPFS can redirect these requests to your local IPFS node, while those that don't can fetch the resource from the ipfs.io gateway.
# e.g
https://ipfs.io/ipfs/Qme7ss3ARVgxv6rXqVPiikMJ8u2NLgmgszg13pYrDKEoiu
You can swap out ipfs.io for your own http-to-ipfs gateway, but you are then obliged to keep that gateway running forever. If your gateway goes down, users with IPFS aware tools will still be able to fetch the content from the IPFS network as long as any node still hosts it, but for those without, the link will be broken. Don't do that.
Nodes on the IPFS network can automatically cache resources they download, and keep those resources available for other nodes. This system depends on nodes being willing and able to cache and share resources with the network. Storage is finite, so nodes need to clear out some of their previously cached resources to make room for new resources. This process is called garbage collection.To assure the existence of the NFT's metadata and content they must both be not just written to IPFS but also pinned to at least one IPFS node.
To ensure that data persists on IPFS, and is not deleted during garbage collection, data can be pinned to one or more IPFS nodes. Pinning gives you control over disk space and data retention. As such, you should use that control to pin any content you wish to keep on IPFS indefinitely.
To ensure that your important data is retained, you may want to use a pinning service. These services run lots of IPFS nodes and allow users to pin data on those nodes for a fee. Some services offer free storage-allowance for new users. Pinning services are handy when:Thus to assure the existence of the NFT's metadata and content pinning must be rented from a pinning service, another single point of failure.
- You don't have a lot of disk space, but you want to ensure your data sticks around.
- Your computer is a laptop, phone, or tablet that will have intermittent connectivity to the network. Still, you want to be able to access your data on IPFS from anywhere at any time, even when the device you added it from is offline.
- You want a backup that ensures your data is always available from another computer on the network if you accidentally delete or garbage-collect your data on your own computer.
But functionally, IPFS works the same way as BitTorrent with magnet links — if nobody bothers seeding your file, there’s no file there. Nifty Gateway turn out not to bother to seed literally the files they sold, a few weeks later. [Twitter; Twitter]Anil Dash claims to have invented, with Kevin McCoy, the concept of NFTs referencing Web URLs in 2014. He writes in his must-read NFTs Weren’t Supposed to End Like This:
Seven years later, all of today’s popular NFT platforms still use the same shortcut. This means that when someone buys an NFT, they’re not buying the actual digital artwork; they’re buying a link to it. And worse, they’re buying a link that, in many cases, lives on the website of a new start-up that’s likely to fail within a few years. Decades from now, how will anyone verify whether the linked artwork is the original?My only disagreement with Dash is that, as someone who worked on archiving the "old-fashioned pre-blockchain internet" for two decades, I don't believe that there is a new-fangled post-blockchain Internet that makes the problems go away. And neither does David Gerard:
All common NFT platforms today share some of these weaknesses. They still depend on one company staying in business to verify your art. They still depend on the old-fashioned pre-blockchain internet, where an artwork would suddenly vanish if someone forgot to renew a domain name. “Right now NFTs are built on an absolute house of cards constructed by the people selling them,” the software engineer Jonty Wareing recently wrote on Twitter.
The pictures for NFTs are often stored on the Interplanetary File System, or IPFS. Blockchain promoters talk like IPFS is some sort of bulletproof cloud storage that works by magic and unicorns.2021-04-16T00:18:47+00:00 David. (noreply@blogger.com) Journal of Web Librarianship: The Impact of the COVID-19 Pandemic on Digital Library Usage: A Public Library Case Study https://www.tandfonline.com/doi/full/10.1080/19322909.2021.1913465?ai=1dl&mi=co84bk&af=R .
The Evergreen Community is pleased to announce the release of Evergreen 3.7.0. Evergreen is highly-scalable software for libraries that helps library patrons find library materials and helps libraries manage, catalog, and circulate those materials, no matter how large or complex the libraries.
Evergreen 3.7.0 is a major release that includes the following new features of note:
Evergreen admins installing or upgrading to 3.7.0 should be aware of the following:
open-ils.geo.Geo::Coder::Google, Geo::Coder::OSM, String::KeyboardDistance, and Text::Levenshtein::Damerau::XS.The release is available on the Evergreen downloads page. Additional information, including a full list of new features, can be found in the release notes.
2021-04-14T19:54:32+00:00 Galen Charlton Lucidworks: Build Semantic Search at Speed https://lucidworks.com/post/how-to-build-fast-semantic-search/Learn more about using semantic machine learning methodologies to power more relevant search results across your organization.
The post Build Semantic Search at Speed appeared first on Lucidworks.
2021-04-14T17:06:13+00:00 Elizabeth Edmiston Open Knowledge Foundation: Unveiling the new Frictionless Data documentation portal https://blog.okfn.org/2021/04/14/unveiling-the-new-frictionless-data-documentation-portal/
Have you used Frictionless Data documentation in the past and been confused or wanted more examples? Are you a brand new Frictionless Data user looking to get started learning?
We invite you all to visit our new and improved documentation portal.
Thanks to a fund that the Open Knowledge Foundation was awarded from the Open Data Institute, we have completely reworked the guides of our Frictionless Data Framework website according to the suggestions from a cohort of users gathered during several feedback sessions throughout the months of February and March.
We cannot stress enough how precious those feedback sessions have been to us. They were an excellent opportunity to connect with our users and reflect together with them on how to make all our guides more useful for current and future users. The enthusiasm and engagement that the community showed for the process was great to see and reminded us that the link with the community should be at the core of open source projects.
We were amazed by the amount of extremely useful inputs that we got. While we are still digesting some of the suggestions and working out how to best implement them, we have made many changes to make the documentation a smoother, Frictionless experience.
A common theme from the feedback sessions was that it was sometimes difficult for novice users to understand the whole potential of the Frictionless specifications. To help make this clearer, we added a more detailed explanation, user examples and user stories to our Introduction. We also added some extra installation tips and a troubleshooting section to our Quick Start guide.
The users also suggested several code changes, like more realistic code examples, better explanations of functions, and the ability to run code examples in both the Command Line and Python. This last suggestion was prompted because most of the guides use a mix of Command Line and Python syntax, which was confusing to our users. We have clarified that by adding a switch in the code snippets that allows user to work with a pure Python Syntax or pure Command Line (when possible), as you can see here. We also put together an FAQ section based on questions that were often asked on our Discord chat. If you have suggestions for other common questions to add, let us know!
The documentation revamping process also included the publication of new tutorials. We worked on two new Frictionless tutorials, which are published under the Notebooks link in the navigation menu. While working on those, we got inspired by the feedback sessions and realised that it made sense to give our community the possibility to contribute to the project with some real life examples of Frictionless Data use. The user selection process has started and we hope to get the new tutorials online by the end of the month, so stay tuned!
Our commitment to continually improving our documentation is not over with this project coming to an end! Do you have suggestions for changes you would like to see in our documentation? Please reach out to us or open a pull request to contribute. Everyone is welcome to contribute! Learn how to do it here.
Once again, we are very grateful to the Open Data Institute for giving us the chance to focus on this documentation in order to improve it. We cannot thank enough all our users who took part in the feedback sessions. Your contributions were precious.
Frictionless Data is a set of specifications for data and metadata interoperability, accompanied by a collection of software libraries that implement these specifications, and a range of best practices for data management. The project is funded by the Sloan Foundation.
2021-04-14T11:22:28+00:00 Sara Petti David Rosenthal: Cryptocurrency's Carbon Footprint https://blog.dshr.org/2021/04/cryptocurrencys-carbon-footprint.html China’s bitcoin mines could derail carbon neutrality goals, study says and Bitcoin mining emissions in China will hit 130 million tonnes by 2024, the headlines say it all. Excusing this climate-destroying externality of Proof-of-Work blockchains requires a continuous flow of new misleading arguments. Below the fold I discuss one of the more recent novelties.Bitcoin transactions themselves don’t cause a lot of power usage. Getting the network to accept a transaction consumes almost no power, but having ASIC miners grind through the mathematical ether to solve valid blocks does. Miners are incentivized to do this because they are compensated for it. Presently, that compensation includes a block reward which is paid in bitcoin (6.25 BTC per block) as well as a miner fee (transaction fee). Transaction fees are denominated in fractional bitcoins and paid by the initiator of the transaction. Today, about 15% of total miners’ rewards are transactions fees, and about 85% are block rewards.So, he argues, Bitcoin's current catastrophic carbon footprint doesn't matter because, as the reward decreases, so will the carbon footprint:
This also means that the power usage of the Bitcoin network won’t scale linearly with the number of transactions as the network becomes predominantly fee-based and less rewards-based (which causes a lot of power to the thrown at it in light of increasing BTC prices), and especially if those transactions take place on secondary layers. In other words, taking the ratio of “Bitcoin’s total power usage” to “Number of transactions” to calculate the “Power cost per transaction” falsely implies that all transactions hit the final settlement layer (they don’t) and disregards the fact that the final state of the Bitcoin base layer is a fee-based state which requires a very small fraction of Bitcoin’s overall power usage today (no more block rewards).Seibert has some vague idea that there are implications of this not just for the carbon footprint but also for the security of the Bitcoin blockchain:
Going forward however, miners’ primary revenue source will change from block rewards to the fees paid for the processing of transactions, which don’t per se cause high carbon emissions. Bitcoin is set to become be a purely fee-based system (which may pose a risk to the security of the system itself if the overall hash rate declines, but that’s a topic for another article because a blockchain that is fully reliant on fees requires that BTCs are transacted with rather than held in Michael Saylor-style as HODLing leads to low BTC velocity, which does not contribute to security in a setup where fees are the only rewards for miners.)Lets leave aside the stunning irresponsibility of arguing that it is acceptable to dump huge amounts of long-lasting greenhouse gas into the atmosphere now because you believe that in the future you will dump less. How realistic is the idea that decreasing the mining reward will decrease the carbon footprint?

An attacker could (i) spend Bitcoins, i.e., engage in a transaction in which he sends his Bitcoins to some merchant in exchange for goods or assets; then (ii) allow that transaction to be added to the public blockchain (i.e., the longest chain); and then subsequently (iii) remove that transaction from the public blockchain, by building an alternative longest chain, which he can do with certainty given his majority of computing power. The merchant, upon seeing the transaction added to the public blockchain in (ii), gives the attacker goods or assets in exchange for the Bitcoins, perhaps after an escrow period. But, when the attacker removes the transaction from the public blockchain in (iii), the merchant effectively loses his Bitcoins, allowing the attacker to “double spend” the coins elsewhere.Such attacks are endemic among the smaller alt-coins; for example there were three successful attacks on Ethereum Classic in a single month last year. Clearly, Seibert's future "transaction only" Bitcoin must defend against them.
From a computer security perspective, the key thing to note ... is that the security of the blockchain is linear in the amount of expenditure on mining power, ... In contrast, in many other contexts investments in computer security yield convex returns (e.g., traditional uses of cryptography) — analogously to how a lock on a door increases the security of a house by more than the cost of the lock.Lets consider the possible futures of a fee-based Bitcoin blockchain. It turns out that currently fee revenue is a smaller proportion of total miner revenue than Seibert claims. Here is the chart of total revenue (~$60M/day):


 |
| Short vs. Long |
In this section we will assume q < p [i.e., that the attacker does not have a majority]. Otherwise, all bets are off with the current Bitcoin protocol ... The honest miners, who no longer receive any rewards, would quit due to lack of incentive; this will make it even easier for the attacker to maintain his dominance. This will cause either the collapse of Bitcoin or a move to a modified protocol. As such, this attack is best seen as an attempt to destroy Bitcoin, motivated not by the desire to obtain Bitcoin value, but rather wishing to maintain entrenched economical systems or obtain speculative profits from holding a short position.Short interest in Bitcoin is currently small relative to the total stock, but much larger relative to the circulating supply. Budish analyzes various sabotage attack cases, with a parameter ∆attack representing the proportion of the Bitcoin value destroyed by the attack:
For example, if ∆attack = 1, i.e., if the attack causes a total collapse of the value of Bitcoin, the attacker loses exactly as much in Bitcoin value as he gains from double spending; in effect, there is no chance to “double” spend after all. ... However, ∆attack is something of a “pick your poison” parameter. If ∆attack is small, then the system is vulnerable to the double-spending attack ... and the implicit transactions tax on economic activity using the blockchain has to be high. If ∆attack is large, then a short time period of access to a large amount of computing power can sabotage the blockchain.The current cryptocurrency bubble ensures that everyone is making enough paper profits from the golden eggs to deter them from killing the goose that lays them. But it is easy to create scenarios in which a rush for the exits might make killing the goose seem like the best way out.
If joining the replica set of a permissionless blockchain is free, it will be vulnerable to Sybil attacks, in which an attacker creates many apparently independent replicas which are actually under his sole control. If creating and maintaining a replica is free, anyone can authorize any change they choose simply by creating enough Sybil replicas.There are many attempts to provide less environmentally damaging ways to make adding a block to a blockchain expensive, but attempts to make adding a block cheaper are self-defeating because they make the blockchain less secure.
Defending against Sybil attacks requires that membership in a replica set be expensive.
We are happy to announce the date of our next Open Meeting! Join us on April 27, 2021 any time between 10:00-2:00pm EDT. The Open Meetings are drop-in style sessions where users of all levels and abilities gather to ask questions, share use cases and get updates on Islandora. There will be experienced Islandora 8 users on hand to answer questions or give demos. We would love for your to join us any time during the 4-hour window, so feel free to pop by any time!
More details about the Open Meeting, and the Zoom link to join, are in this Google doc.
Registration is not required. If you would like a calendar invite as a reminder, please let us know at community@islandora.ca.

The NDSA is very pleased to announce the Call for Proposals is open for Digital Preservation 2021: Embracing Digitality (#DigiPres21) to be held ONLINE this year on November 4th, 2021 during World Digital Preservation Day.
Submissions from members and nonmembers alike are welcome, and you can learn more about session format options through the CFP. The deadline to submit proposals is Monday, May 17, at 11:59pm Eastern Time.
Digital Preservation 2021 (#DigiPres21) is held in partnership with our host organization, the Council on Library and Information Resources’ (CLIR) Digital Library Federation. Separate calls are being issued for CLIR+DLF’s 2021 events, the 2021 DLF Forum (November 1-3) and associated workshop series Learn@DLF (November 8-10). NDSA strives to create a safe, accessible, welcoming, and inclusive event, and adheres to DLF’s Code of Conduct.
We look forward to seeing you online on November 4th,
~ 2021 DigiPres Planning Committee
The post Call for Proposals open for NDSA Digital Preservation 2021! appeared first on DLF.
2021-04-13T13:58:22+00:00 kussmann HangingTogether: Dutch round table on next generation metadata: think bigger than NACO and WorldCat http://feedproxy.google.com/~r/Hangingtogetherorg/~3/jk2gsfc1Ez8/As part of the OCLC Research Discussion Series on Next Generation Metadata, this blog post reports back from the Dutch language round table discussion held on March 8, 2021. (A Dutch translation is available here).
Librarians – with backgrounds in metadata, library systems, reference work, national bibliography, and back-office processes – joined the session, representing a nice mix of academic and heritage institutions from the Netherlands and Belgium. The participants were engaged, candid, and thoughtful and this stimulated constructive knowledge exchange in a pleasant atmosphere.
Map of next-gen metadata projects (Dutch session)As in all the other round table discussions, participants started with taking stock of next generation metadata projects in their region or initiatives they were aware of elsewhere. The resulting map shows a strong representation of bibliographic and cultural heritage data-projects (see upper- and lower-left quadrants of the matrix). Several next-generation metadata research projects of the National Library of the Netherlands were listed and described, such as:
The Digital Heritage Reference Architecture (DERA) was developed as part of the national strategy for digital heritage in the Netherlands. It is a framework for managing and publishing heritage information as Linked Open Data (LOD), according to agreed practices and conventions. The Van Gogh Worldwide platform is an exemplar of the application of DERA – where metadata, relating to the painter’s art works residing at 17 different Dutch heritage institutions and private collectors, have been pulled from source systems by API.
A noteworthy initiative listed in the RIM/Scholarly Communications quadrant of the matrix is the NL-Open Knowledge Base, an initiative in the context of last year’s deal between Elsevier and the Dutch Research institutions, to jointly develop open science services based on their RIM systems, Elsevier’s databases and analytics solutions and the Dutch funding organizations’ databases. The envisaged Open Knowledge Base could potentially feed new applications – for example, a dashboard to monitor the achievement of the universities’ Sustainable Development Goals – and allow to significantly improve the analysis of research impact.
Notwithstanding the state-of-the-art projects mentioned during the mapping exercise, the participants were impatient about the pace of the transition to the next generation of metadata. One participant experienced frustration with having to use multiple tools for a workflow that supports the transition, namely: integration of PIDs, local authorities, or links to and from external sources. Another participant noted that there is still a lot of efficiency to be gained in the value chain:
“When we look at the supply chain, it is absurd to start from scratch because there is already so much data. When a book comes out on the market, it must already have been described. There should not be a need to start from scratch in the library.”
The group also wondered – with so many bibliographic datasets already published as Linked Open Data – what else needs to be done to interconnect them in meaningful ways?
The question of what is keeping us from moving forward dominated the discussion.
One participant suggested that libraries are cautious about the data sources they link up with. Authority files are persistent and reliable data sources, which have yet to find their counterparts in the newly emerging linked data ecosystem. The lack of conventions around reliability and persistence might be a reason why libraries are hesitant entering into linked data partnerships or holding back from relying on external data – even from established sources, such as Wikidata. After all, linking to a data source is an indication of trust and recognition of data quality.
The conversation moved to data models: which linked data do you create yourself? How will you design it and link it up to other data? Some participants found there was still a lack of agreement and clarity about the meaning of key concepts such as a “work”. Others pointed out that defining the meaning of concepts used is exactly what linked data is about and this feature allows the co-existence of multiple ontologies – in other words, there is no need any longer to fix semantics in hard standards.
“There is no unique semantic model. When you refer to data that has already been defined by others, you relinquish control over that piece of information, and that can be a mental barrier against doing linked data the proper way. It is much safer to store and manage all the data in your own silo. But the moment you can let go of that, the world can become much richer than you can ever achieve on your own.”
The conversation turned to the need to train cataloging staff. One participant thought it would be helpful to get started by learning to think in terms of linked data, to mentally practice building linked data graphs and play with different possible structures, as one does with LEGO bricks. The group agreed there is still too little understanding of the possibilities and of the consequences of practicing linked data.
“We have to learn to see ourselves as publishers of metadata, so that others can find it – but we have no idea who the others are, we have to think even bigger than the Library of Congress’s NACO or WorldCat. We are no longer talking about the records we create, but about pieces of records that are unique, because a lot already comes from elsewhere. We have to wrap our minds around this and ask ourselves: What is our role in the bigger picture? This is very hard to do!”
The group thought it was very important to start having that discussion within the library. But how exactly do you do that? It’s a big topic and it must be initiated by the library’s leadership team.
One university library leader in the group reacted to this and said:
“What strikes me is that the number of libraries faced with this challenge is shrinking. (…) [In my library] we hardly produce any metadata anymore. (…) If we look at what we still produce ourselves, it is about describing photos of student fraternities (…). It’s almost nothing anymore. Metadata has really become a topic for a small group of specialists.”
The group objected that this observation was overlooking the importance of the discovery needs of the communities libraries serve. However provocative this observation was, it reflects a reality that we need to acknowledge and at the same time put in perspective. Alas, there was no time for that, as the session was wrapping up. It had certainly been a conversation to be continued!
In March 2021, OCLC Research conducted a discussion series focused on two reports:
The round table discussions were held in different European languages and participants were able share their own experiences, get a better understanding of the topic area, and gain confidence in planning ahead.
The Opening Plenary Session opened the forum for discussion and exploration and introduced the theme and its topics. Summaries of all eight round table discussions are published on the OCLC Research blog, Hanging Together. This is the last post and it is preceded by the posts reporting on the first English session, the Italian session, the second English session, the French session, the German session, the Spanish session and the third English session.
The Closing Plenary Session on April 13 will synthesize the different round table discussions. Registration is still open for this webinar: please join us!
The post Dutch round table on next generation metadata: think bigger than NACO and WorldCat appeared first on Hanging Together.
 The Association of Moving Image Archivists (AMIA) and DLF will be sending Justine Thomas to attend the 2021 virtual DLF/AMIA Hack Day and AMIA spring conference! As this year’s “cross-pollinator,” Justine will enrich both the Hack Day event and the AMIA conference, sharing a vision of the library world from her perspective.
The Association of Moving Image Archivists (AMIA) and DLF will be sending Justine Thomas to attend the 2021 virtual DLF/AMIA Hack Day and AMIA spring conference! As this year’s “cross-pollinator,” Justine will enrich both the Hack Day event and the AMIA conference, sharing a vision of the library world from her perspective.
Justine Thomas (@JustineThomasM) is currently a Digital Programs Contractor at the National Museum of American History (NMAH) focusing on digital asset management and collections information support. Prior to graduating in 2019 with a Master’s in Museum Studies from the George Washington University, Justine worked at NMAH as a collections processing intern in the Archives Center and as a Public Programs Facilitator encouraging visitors to discuss American democracy and social justice issues.
![]()
![]()
The seventh AMIA+DLF Hack Day (online April 1-15) will be a unique opportunity for practitioners and managers of digital audiovisual collections to join with developers and engineers to remotely collaborate to develop solutions for digital audiovisual preservation and access.
The goal of the AMIA + DLF Award is to bring “cross-pollinators”–developers and software engineers who can provide unique perspectives to moving image and sound archivists’ work with digital materials, share a vision of the library world from their perspective, and enrich the Hack Day event–to the conference.
Find out more about this year’s Hack Day activities here.
The post 2021 AMIA Cross-Pollinator: Justine Thomas appeared first on DLF.
2021-04-12T19:19:57+00:00 Gayle Evergreen ILS: Evergreen 3.7-rc available https://evergreen-ils.org/evergreen-3-7-rc-available/The Evergreen Community is pleased to announce the availability of the release candidate for Evergreen 3.7. This release follows up on the recent beta release. The general release of 3.7.0 is planned for Wednesday, 14 April 2021. Between now and then, please download the release candidate and try it out.
Additional information, including a full list of new features, can be found in the release notes.
2021-04-12T18:21:26+00:00 Galen Charlton Jez Cope: Intro to the fediverse https://erambler.co.uk/blog/intro-to-the-fediverse/Wow, it turns out to be 10 years since I wrote this beginners guide to Twitter. Things have moved on a loooooong way since then.
Far from being the interesting, disruptive technology it was back then, Twitter has become part of the mainstream, the establishment. Almost everyone and everything is on Twitter now, which has both pros and cons.
It’s now possible to follow all sorts of useful information feeds, from live updates on transport delays to your favourite sports team’s play-by-play performance to an almost infinite number of cat pictures. In my professional life it’s almost guaranteed that anyone I meet will be on Twitter, meaning that I can contact them to follow up at a later date without having to exchange contact details (and they have options to block me if they don’t like that).
On the other hand, a medium where everyone’s opinion is equally valid regardless of knowledge or life experience has turned some parts of the internet into a toxic swamp of hatred and vitriol. It’s easier than ever to forget that we have more common ground with any random stranger than we have similarities, and that’s led to some truly awful acts and a poisonous political arena.
Part of the problem here is that each of the social media platforms is controlled by a single entity with almost no accountability to anyone other than shareholders. Technological change has been so rapid that the regulatory regime has no idea how to handle them, leaving them largely free to operate how they want. This has led to a whole heap of nasty consequences that many other people have done a much better job of documenting than I could (Shoshana Zuboff’s book The Age of Surveillance Capitalism is a good example). What I’m going to focus on instead are some possible alternatives.
If you accept the above argument, one obvious solution is to break up the effective monopoly enjoyed by Facebook, Twitter et al. We need to be able to retain the wonderful affordances of social media but democratise control of it, so that it can never be dominated by a small number of overly powerful players.
There’s actually a thing that already exists, that almost everyone is familiar with and that already works like this.
It’s email.
There are a hundred thousand email servers, but my email can always find your inbox if I know your address because that address identifies both you and the email service you use, and they communicate using the same protocol, Simple Mail Transfer Protocol (SMTP)1. I can’t send a message to your Twitter from my Facebook though, because they’re completely incompatible, like oil and water. Facebook has no idea how to talk to Twitter and vice versa (and the companies that control them have zero interest in such interoperability anyway).
Just like email, a federated social media service like Mastodon allows you to use any compatible server, or even run your own, and follow accounts on your home server or anywhere else, even servers running different software as long as they use the same ActivityPub protocol.
There’s no lock-in because you can move to another server any time you like, and interact with all the same people from your new home, just like changing your email address. Smaller servers mean that no one server ends up with enough power to take over and control everything, as the social media giants do with their own platforms. But at the same time, a small server with a small moderator team can enforce local policy much more easily and block accounts or whole servers that host trolls, nazis or other poisonous people.
I have no problem with anyone for choosing to continue to use what we’re already calling “traditional” social media; frankly, Facebook and Twitter are still useful for me to keep in touch with a lot of my friends. However, I do think it’s useful to know some of the alternatives if only to make a more informed decision to stick with your current choices. Most of these services only ask for an email address when you sign up and use of your real name vs a pseudonym is entirely optional so there’s not really any risk in signing up and giving one a try. That said, make sure you take sensible precautions like not reusing a password from another account.
| Instead of… | Try… |
|---|---|
| Twitter, Facebook | Mastodon, Pleroma, Misskey |
| Slack, Discord, IRC | Matrix |
| WhatsApp, FB Messenger, Telegram | Also Matrix |
| Instagram, Flickr | PixelFed |
| YouTube | PeerTube |
| The web | Interplanetary File System (IPFS) |
Which, if you can believe it, was formalised nearly 40 years ago in 1982 and has only had fairly minor changes since then! ↩︎
Thanks to George Bingham, UK Account Manager at OCLC, for contributing this post as part of the Metadata Series blog posts.
As part of the OCLC Research Discussion Series on Next Generation Metadata, this blog post reports back from the third English language round table discussion held on March 23, 2021. The session was scheduled to facilitate a UK-centric discussion with a panel of library representatives from the UK with backgrounds in bibliographic control, special collections, collections management, metadata standards and computer science – a diverse and engaged discussion group.
 Map of next-gen metadata projects (third English session)
Map of next-gen metadata projects (third English session)As with other round table sessions, the group started with mapping next generation metadata projects that participants were aware of, on a 2×2 matrix characterizing the application area: bibliographic data, cultural heritage data, research information management (RIM) data, and for anything else, the category, “Other”. The resulting map gave a nice overview of some of the building blocks of the emerging next generation metadata infrastructure, focussing in this session on the various national and international identifier initiatives – ISNI, VIAF, FAST, LC/NACO authority file and LC/SACO subject lists, and ORCID – and metadata and linked data infrastructure projects such as Plan-M (an initiative, facilitated by Jisc, to rethink the way that metadata for academic and specialist libraries is created, sold, licensed, shared, and re-used in the UK), BIBFrame and OCLC’s Shared Entity Management Infrastructure.
The map also raises interesting questions about some of the potential or actual obstacles to the spread of next generation metadata:
What to do about missing identifiers? How to incorporate extant regional databases and union catalogs into the national and international landscape? How “open” are institutions’ local archive management systems? Who is willing to pay for linked data?
The discussion panel agreed that there is a pressing need for metadata to be less hierarchical, which linked data delivers, and that a collaborative approach is the best way forward. One example is the development of the UK funnel for NACO and SACO, which has reinforced the need for a more national approach in the UK. The funnel allows the UK Higher Education institutions to contribute to the LC name and subject authorities using a single channel – rather than each library setting up its own channel. Because they work together as a group to make their contributions to the authority files, the quality and the “authority” of their contributions is significantly increased.
One panelist reported on a one-year trial with ISNI for the institution’s legal deposit library, as a first step into working with linked data. It is hoped that it will prove to be a sustainable way forward. There is considerable enthusiasm and interest for this project amongst the institution’s practitioners, a vital ingredient for a successful next generation metadata initiative.
Another panelist expanded on several ongoing projects with the aim of embedding ISNI identifiers within the value chain and getting them out to where cataloguers can pick them up. For example, publishers are starting to use them in their ONIX feeds to enable them to create clusters of records. Also, cataloging agencies in the UK are being supplied with ISNI identifiers so that they can embed them in the metadata at source, in the cataloging-in-publication (CIP) metadata, that they supply to libraries in the UK.
Efforts are also under way to systematically match ISNI entries against VIAF entries, and to provide a reconciliation file to enable OCLC to update the VIAF with the most recent ISNI. These could then be fed through to the Library of Congress, who can then use these to update NACO files.
With 6 million files to update, this is a perfect example of a leading edge dynamic next generation metadata initiative that will have to overcome the considerable challenge of scalability for it to succeed at a global level.
The discussion moved on to the other challenges faced by identifier schemes. It was noted that encouraging a more widespread collaborative approach would rely on honesty amongst the contributors. There would need to be built in assurances that the tags/data come from a trusted source. Would the more collaborative approach introduce too much scope for duplicate identifiers being created, and too many variations on preferred names? Cultural expectations would have to be clearly defined and adhered to. And last but by no means least is the challenge of providing the resources needed to upscale to a national and international scope.
Participants raised concerns that library management systems are not keeping pace with current discussions on next generation metadata or with real world implementations, to the extent that they may be the biggest obstacle in the move towards next generation metadata. It was recognized that moving to linked data involves a big conceptual and technical leap from the current string-based metadata creation, sharing and management practices, tools and methodologies.
Progress can only be made in small steps, and there is still much work to be done to demonstrate the benefits of next generation metadata, a prerequisite if we are to complete the essential step of gaining the support of senior management and buy-in from system suppliers.
Towards the end of the session, a brief discussion arose around the possibility (and danger) of organizations outside the library sector “taking over” if we can’t manage the transition ourselves. Amazon was cited as already becoming regarded as a good model to follow for metadata standards, despite what we know to be its shortcomings: it does not promote high quality data, and there are numerous problems concealed within the data, that are not evident to non-professionals. These quality issues would become very problematic if they are allowed to become pervasive in the global metadata landscape.
“Our insistence on ‘perfect data’ is a good thing, but are people just giving up on it because it’s too difficult to attain?”
In March 2021, OCLC Research conducted a discussion series focused on two reports:
The round table discussions were held in different European languages and participants were able share their own experiences, get a better understanding of the topic area, and gain confidence in planning ahead.
The Opening Plenary Session opened the forum for discussion and exploration and introduced the theme and its topics. Summaries of all eight round table discussions are published on the OCLC Research blog, Hanging Together. This post is preceded by the posts reporting on the first English session, the Italian session, the second English session, the French session, the German session, and the Spanish session.
The Closing Plenary Session on April 13 will synthesize the different round table discussions. Registration is still open for this webinar: please join us!
The post Third English round table on next generation metadata: investing in the utility of authorities and identifiers appeared first on Hanging Together.
Over the weekend, I posted an article here about pre-recording conference talks and sent a tweet about the idea on Monday. I hoped to generate discussion about recording talks to fill in gaps—positive and negative—about the concept, and I was not disappointed. I’m particularly thankful to Lisa Janicke Hinchliffe and Andromeda Yelton along with Jason Griffey, Junior Tidal, and Edward Lim Junhao for generously sharing their thoughts. Daniel S and Kate Deibel also commented on the Code4Lib Slack team. I added to the previous article’s bullet points and am expanding on some of the issues here. I’m inviting everyone mentioned to let me know if I’m mischaracterizing their thoughts, and I will correct this post if I hear from them. (I haven’t found a good comments system to hook into this static site blog.)
Lisa Janicke Hinchliffe made this point early in the feedback:
@DataG For me downside is it forces every session into being a lecture. For two decades CfPs have emphasized how will this season be engaging/not just a talking head? I was required to turn workshops into talks this year. Even tho tech can do more. Not at all best pedagogy for learning
— Lisa Janicke Hinchliffe (@lisalibrarian) April 5, 2021
Jason described the “flipped classroom” model that he had in mind as the NISOplus2021 program was being developed. The flipped classroom model is one where students do the work of reading material and watching lectures, then come to the interactive time with the instructors ready with questions and comments about the material. Rather than the instructor lecturing during class time, the class time becomes a discussion about the material. For NISOplus, “the recording is the material the speaker and attendees are discussing” during the live Zoom meetings.
In the previous post, I described how the speaker could respond in text chat while the recording replay is beneficial. Lisa went on to say:
@DataG Q+A is useful but isn't an interactive session. To me, interactive = participants are co-creating the session, not watching then commenting on it.
— Lisa Janicke Hinchliffe (@lisalibrarian) April 5, 2021
She described an example: the SSP preconference she ran at CHS. I’m paraphrasing her tweets in this paragraph. The preconference had a short keynote and an “Oprah-style” panel discussion (not pre-prepared talks). This was done live; nothing was recorded. After the panel, people worked in small groups using Zoom and a set of Google Slides to guide the group work. The small groups reported their discussions back to all participants.
Andromeda points out (paraphrasing twitter-speak): “Presenters will need much more— and more specialized—skills to pull it off, and it takes a lot more work.” And Lisa adds: “Just so there is no confusion … I don’t think being online makes it harder to do interactive. It’s the pre-recording. Interactive means participants co-create the session. A pause to chat isn’t going to shape what comes next on the recording.”
@ThatAndromeda @DataG Totally agree on this. I had to pre-record a conference presentation recently and it was a terrible experience, logistically. I feel like it forces presenters to become video/sound editors, which is obviously another thing to worry about on top of content and accessibility.
— Junior Tidal (@JuniorTidal) April 5, 2021
Andromeda also agreed with this: “I will say one of the things I appreciated about NISO is that @griffey did ALL the video editing, so I was not forced to learn how that works.” She continued, “everyone has different requirements for prerecording, and in [Code4Lib’s] case they were extensive and kept changing.” And later added: “Part of the challenge is that every conference has its own tech stack/requirements. If as a presenter I have to learn that for every conference, it’s not reducing my workload.”
It is hard not to agree with this; a high-quality (stylistically and technically) recording is not easy to do with today’s tools. This is also a technical burden for meeting organizers. The presenters will put a lot of work into talks—including making sure the recordings look good; whatever playback mechanism is used has to honor the fidelity of that recording. For instance, presenters who have gone through the effort to ensure the accessibility of the presentation color scheme want the conference platform to display the talk “as I created it.”
The previous post noted that recorded talks also allow for the creation of better, non-real-time transcriptions. Lisa points out that presenters will want to review that transcription for accuracy, which Jason noted adds to the length of time needed before the start of a conference to complete the preparations.
@ThatAndromeda @DataG @griffey Even if prep is no more than the time it would take to deliver live (which has yet to be case for me and I'm good at this stuff), it is still double the time if you are expected to also show up live to watch along with everyone else.
— Lisa Janicke Hinchliffe (@lisalibrarian) April 5, 2021
This is a consideration I hadn’t thought through—that presenters have to devote more clock time to the presentation because first they have to record it and then they have to watch it. (Or, as Andromeda added, “significantly more than twice the time for some people, if they are recording a bunch in order to get it right and/or doing editing.”)
@DataG @griffey 3) No. Audience. Reaction. I give a joke and no one laughs. Was it funny? Was it not funny? Talks are a *performance* and a *relationship*; I'm getting energy off the audience, I'm switching stuff on the fly to meet their vibe. Prerecorded/webinar is dead. Feels like I'm bombing.
— Andromeda Yelton (@ThatAndromeda) April 5, 2021
Wow, yes. I imagine it would take a bit of imagination to get in the right mindset to give a talk to a small camera instead of an audience. I wonder how stand-up comedians are dealing with this as they try to put on virtual shows. Andromeda summed this up:
@DataG @griffey oh and I mean 5) I don't get tenure or anything for speaking at conferences and goodness knows I don't get paid. So the ENTIRE benefit to me is that I enjoy doing the talk and connect to people around it. prerecorded talk + f2f conf removes one of these; online removes both.
— Andromeda Yelton (@ThatAndromeda) April 5, 2021
Also in this heading could be “No Speaker Reaction”—or the inability for subsequent speakers at a conference to build on something that someone said earlier. In the Code4Lib Slack team, Daniel S noted: “One thing comes to mind on the pre-recording [is] the issue that prerecorded talks lose the ‘conversation’ aspect where some later talks at a conference will address or comment on earlier talks.” Kate Deibel added: “Exactly. Talks don’t get to spontaneously build off of each other or from other conversations that happen at the conference.”
Lisa points out that pre-recording talks before en event means there is a delay between the recording and the playback. In the example she pointed out, there was a talk at RLUK that pre-recorded would have been about the University of California working on an Open Access deal with Elsevier; live, it was able to be “the deal we announced earlier this week”.
Near the end of the discussion, Lisa added:
@DataG @griffey @ThatAndromeda I also recommend going forward that the details re what is required of presenters be in the CfP. It was one thing for conferences that pivoted (huge effort!) but if you write the CfP since the pivot it should say if pre-record, platform used, etc.
— Lisa Janicke Hinchliffe (@lisalibrarian) April 5, 2021
…and Andromeda added: “Strong agree here. I understand that this year everyone was making it up as they went along, but going forward it’d be great to know that in advance.”
That means conferences will need to take these needs into account well before the Call for Proposals (CfP) is published. A conference that is thinking now about pre-recording their talks must work through these issues and set expectations with presenters early.
As I hoped, the Twiter replies tempered my eagerness for the all-recorded style with some real-world experience. There could be possibilities here, but adapting face-to-face meetings to a world with less travel won’t be simple and will take significant thought beyond the issues of technology platforms.
Edward Lim Junhao summarized this nicely: “I favor unpacking what makes up our prof conferences. I’m interested in recreating that shared experience, the networking, & the serendipity of learning sth you didn’t know. I feel in-person conferences now have to offer more in order to justify people traveling to attend them.”
Related, Andromeda said: “Also, for a conf that ultimately puts its talks online, it’s critical that it have SOMEthing beyond content delivery during the actual conference to make it worth registering rather than just waiting for youtube. realtime interaction with the speaker is a pretty solid option.”
If you have something to add, reach out to me on Twitter. Given enough responses, I’ll create another summary. Let’s keep talking about what that looks like and sharing discoveries with each other.
It was a great discussion, and I think I pulled in the major ideas in the summary above. With some guidance from Ed Summers, I’m going to embed the Twitter threads below using Treeverse by Paul Butler. We might be stretching the boundaries of what is possible, so no guarantees that this will be viewable for the long term.
The Code4Lib conference was last week. That meeting used all pre-recorded talks, and we saw the benefits of pre-recording for attendees, presenters, and conference organizers. Should all talks be pre-recorded, even when we are back face-to-face?
Note! After I posted a link to this article on Twitter, there was a great response of thoughtful comments. I've included new bullet points below and summarized the responses in another blog post.
As an entirely virtual conference, I think we can call Code4Lib 2021 a success. Success ≠ Perfect, of course, and last week the conference coordinating team got together on a Zoom call for a debriefing session. We had a lengthy discussion about what we learned and what we wanted to take forward to the 2022 conference, which we’re anticipating will be something with a face-to-face component.
That last sentence was tough to compose: “…will be face-to-face”? “…will be both face-to-face and virtual”? (Or another fully virtual event?) Truth be told, I don’t think we know yet. I think we know with some certainty that the COVID pandemic will become much more manageable by this time next year—at least in North America and Europe. (Code4Lib draws from primarily North American library technologists with a few guests from other parts of the world.) I’m hearing from higher education institutions, though, that travel is going to be severely curtailed…if not for health risk reasons, then because budgets have been slashed. So one has to wonder what a conference will look like next year.
I’ve been to two online conferences this year: NISOplus21 and Code4Lib. Both meetings recorded talks in advance and started playback of the recordings at a fixed point in time. This was beneficial for a couple of reasons. For organizers and presenters, pre-recording allowed technical glitches to be worked through without the pressure of a live event happening. Technology is not nearly perfect enough or ubiquitously spread to count on it working in real-time. 1 NISOplus21 also used the recordings to get transcribed text for the videos. (Code4Lib used live transcriptions on the synchronous playback.) Attendees and presenters benefited from pre-recording because the presenters could be in the text chat channel to answer questions and provide insights. Having the presenter free during the playback offers new possibilities for making talks more engaging: responding in real-time to polls, getting forehand knowledge of topics for subsequent real-time question/answer sessions, and so forth. The synchronous playback time meant that there was a point when (almost) everyone was together watching the same talk—just as in face-to-face sessions.
During the Code4Lib conference coordinating debrief call, I asked the question: “If we saw so many benefits to pre-recording talks, do we want to pre-record them all next year?” In addition to the reasons above, pre-recorded talks benefit those who are not comfortable speaking English or are first-time presenters. (They have a chance to re-do their talk as many times as they need in a much less stressful environment.) “Live” demos are much smoother because a recording can be restarted if something goes wrong. Each year, at least one presenter needs to use their own machine (custom software, local development environment, etc.), and swapping out presenter computers in real-time is risky. And it is undoubtedly easier to impose time requirements with recorded sessions. So why not pre-record all of the talks?
I get it—it would be different to sit in a ballroom watching a recording play on big screens at the front of the room while the podium is empty. But is it so different as to dramatically change the experience of watching a speaker at a podium? In many respects, we had a dry-run of this during Code4Lib 2020. It was at the early stages of the coming lockdowns when institutions started barring employee travel, and we had to bring in many presenters remotely. I wrote a blog post describing the setup we used for remote presenters, and at the end, I said:
I had a few people comment that they were taken aback when they realized that there was no one standing at the podium during the presentation.
Some attendees, at least, quickly adjusted to this format.
For those with the means and privilege of traveling, there can still be face-to-face discussions in the hall, over meals, and social activities. For those that can’t travel (due to risks of traveling, family/personal responsibilities, or budget cuts), the attendee experience is a little more level—everyone is watching the same playback and in the same text backchannels during the talk. I can imagine a conference tool capable of segmenting chat sessions during the talk playback to “tables” where you and close colleagues can exchange ideas and then promote the best ones to a conference-wide chat room. Something like that would be beneficial as attendance grows for events with an online component, and it would be a new form of engagement that isn’t practical now.
There are undoubtedly reasons not to pre-record all session talks (beyond the feels-weird-to-stare-at-an-unoccupied-ballroom-podium reasons). During the debriefing session, one person brought up that having all pre-recorded talks erodes the justification for in-person attendance. I can see a manager saying, “All of the talks are online…just watch it from your desk. Even your own presentation is pre-recorded, so there is no need for you to fly to the meeting.” That’s legitimate.
So if you like bullet points, here’s how it lays out. Pre-recording all talks is better for:
Downsides for pre-recording all talks:
I’m curious to hear of other reasons, for and against. Reach out to me on Twitter if you have some. The COVID-19 pandemic has changed our society and will undoubtedly transform it in ways that we can’t even anticipate. Is the way that we hold professional conferences one of them?
Can we just pause for a moment and consider the decades of work and layers of technology that make a modern teleconference call happen? For you younger folks, there was a time when one couldn’t assume the network to be there. As in: the operating system on your computer couldn’t be counted on to have a network stack built into it. In the earliest years of my career, we were tickled pink to have Macintoshes at the forefront of connectivity through GatorBoxes. Go read the first paragraph of that Wikipedia article on GatorBoxes…TCP/IP was tunneled through LocalTalk running over PhoneNet on unshielded twisted pairs no faster than about 200 kbit/second. (And we loved it!) Now the network is expected; needing to know about TCP/IP is pushed so far down the stack as to be forgotten…assumed. Sure, the software on top now is buggy and bloated—is my Zoom client working? has Zoom’s service gone down?—but the network…we take that for granted. ↩
The Islandora Documentation Interest Group is holding a sprint!
To support the upcoming release of Islandora, the DIG has planned a 2-week documentation, writing-and-updating sprint to occur as part of the release process. To prepare for that effort, we’re going to spend April 19 – 30th on an Auditing Sprint, where volunteers will review existing documentation and complete this spreadsheet, providing a solid overview of the current status of our docs so we know where to best deploy our efforts during the release. This sprint will run alongside the upcoming Pre-Release Code Sprint, so if you’re not up for coding, auditing docs is a great way to contribute during sprint season!
We are looking for volunteers to sign up to take on two sprint roles:
Auditor: Review a page of documentation and fill out a row in the spreadsheet indicating things like the current status (‘Good Enough’ or ‘Needs Work’) , the goal for that particular page (e.g., “Explain how to create an object,” or “Compare Islandora 7 concepts to Islandora 8 concepts”), and the intended audience (Beginners, developers, etc.).
Reviewer: Read through a page that has been audited and indicate if you agree with the auditor’s assessment, add additional notes or suggestions as needed; basically, give a second set of eyes on each page.
You can sign up for the sprint here, and sign up for individual pages here.
Registration is now open for Samvera Virtual Connect 2021! Samvera Virtual Connect will take place April 20th -21st from 11am – 2pm EDT. Registration is free and open to anyone with an interest in Samvera.
This year’s program is packed with presentations and lightning talks of interest to developers, managers, librarians, and other current or potential Samvera Community participants and technology users.
Register and view the full program on the Samvera wiki.
The post Registration now open for Samvera Virtual Connect, April 20 – 21 appeared first on Samvera.
2021-04-08T17:47:13+00:00 Heather Greer Klein Lucidworks: Chatbots for Self-Resolution and Happier Customers https://lucidworks.com/post/chatbots-self-resolution/How chatbots and conversational applications with deep learning are helping customers resolve issues faster than ever.
The post Chatbots for Self-Resolution and Happier Customers appeared first on Lucidworks.
2021-04-08T14:58:38+00:00 Sommer Antrim Digital Library Federation: 2021 DLF Forum, DigiPres, and Learn@DLF Calls for Proposals https://www.diglib.org/2021-dlf-forum-digipres-and-learndlf-calls-for-proposals/
We’re delighted to share that it’s CFP season for CLIR’s annual events.
Based on community feedback, we’ve made the decision to take our events online again in 2021. We look forward to new and better ways to come together—as always, with community at the center.
Our events will take place on the following dates:
For all events, we encourage proposals from members and non-members; regulars and newcomers; digital library practitioners and those in adjacent fields such as institutional research and educational technology; and students, early-career professionals and senior staff alike. Proposals to more than one event are permitted, though please submit different proposals for each.
The DLF Forum and Learn@DLF CFP is here: https://forum2021.diglib.org/call-for-proposals/
NDSA’s Digital Preservation 2021: Embracing Digitality CFP is here: https://ndsa.org/conference/digital-preservation-2021/cfp/
Session options range from 5-minute lighting talks at the Forum to half-day workshops at Learn@DLF, with many options in between.
The deadline for all opportunities is Monday, May 17, at 11:59pm Eastern Time.
If you have any questions, please write to us at forum@diglib.org, and be sure to subscribe to our Forum newsletter to stay up on all Forum-related news. We’re looking forward to seeing you this fall.
-Team DLF
The post 2021 DLF Forum, DigiPres, and Learn@DLF Calls for Proposals appeared first on DLF.
2021-04-08T14:29:01+00:00 Gayle Peter Sefton: What did you do in the lockdowns PT? Part 1 - Music Videos http://ptsefton.com/2021/04/08/lockdowns1/index.htmlPost looks too long? Don't want to read? Here's the summary. Last year Gail McGlinn* and I did the lockdown home-recording thing. We put out at least one song video per week for a year (and counting - we're up to 58 over 53 weeks). Searchable, sortable website here. We learned some things, got better at performing for the phone camera and our microphones and better at mixing and publishing the result.
* Disclosure Gail's my wife. We got married; she proposed, I accepted.
I may I might - Is this the world's best marriage proposal acceptance song? (It did win a prize at a Ukulele festival for best song)
(This post is littered with links to our songs, sorry but there are 58 of them and someone has to link to them.)
In the second quarter of 2020 Gail McGlinn and I went from playing and singing in community music events (jams, gigs, get togethers) at least once a week to being at home every evening, like everyone else. Like lots of people we decided to put our efforts into home recording, not streaming cos that would be pointless for people with basically no audience, but we started making videos and releasing them under our band name Team Happy.
By release I mean "put on Facebook" and "sometimes remember to upload to YouTube".
This post is about that experience and what we learned.
Team Happy is the name we use to perform as a duo at open mic events and the odd community or ukulele festival. We were originally called "The Narrownecks" in honour of where we live, for one gig, but then we found out there's another group with that name. Actually they're much better than us, just go watch them.
Coming in to 2020 we already had a YouTube channel and it had a grand total of two videos on it with a handful of views - as in you could count them on your fingers. It's still a sad thing to behold, how many views we have - but it's not about views it's about getting discovered and having our songs performed by, oh I dunno, Casey Chambers? Keith Urban? (Oh yeah, that would mean we'd need views. Bugger.) Either that or it's about our personal journey and growth as people. Or continuing to contribute to our local music communities in lockdown (which is what Gail says it's about.). Seriously though, we think I called your name and Dry Pebbles would go well on someone else's album.
Dry Pebbles, by Gail McGlinn - a song written tramping through the bush.
I called your name by Peter Sefton
Anyway, in late March we got out our recording gear and started. While phone cameras are fine for the quality of video we need, we wanted to do better than phone-camera sound. (Here's an example of that sound from one of our first recordings on my song Seventeen - it's pretty muddy, like the lighting.)
Seventeen by Peter Sefton
Initial attempts to get good audio involved feeding USB-audio from a sound mixer with a built in audio interface (a Yamaha MX10) into the phone itself and recording an audio track with the video - but this is clunky and you only get two tracks even though the mixer has multiple inputs. We soon graduated to using a DAW - a Digital Audio Workstation with our mixer, still only two tracks but much less mucking around with the phone.
So this is more or less what we ended up with for the first few weeks - We'd record or "track" everything on the computer and then use it again to mix.
There's a thing you have to do to audio files called mastering which means getting them to a suitable volume level and dynamic range for distribution. Without it loud stuff is too quiet and quiet stuff is too quiet, and the music has no punch. This was a complete mystery to me to start with so I paid for online services that use AI to master tracks - kind of but not really making everything louder. At some point I started doing it myself, beginning the long process of learning the mysteries of compression and limiting and saving money. Haven't mastered it yet, though. Mastering is an actual profession, by the way and I'm not going to reach those heights.
In May, we got a new bit of gear, the Tascam Model 12 an all in one mixer-recorder-interface that lets you track (that is record tracks) without a computer - much easier to deal with. A bit later we got a Zoom H5 portable recorder with built in mics and a couple of extra tracks for instruments so we can do stuff away from home - this got used on our month-long holiday in March 2021. Well it was almost a month, but there was a Rain Event and we came home a bit early. These machines let you capture tracks, including adding new ones without touching the computer which is a big win as far as I am concerned.
Gail singing Closer to fine on The Strand in Townsville, in North Queensland, recorded on the H5 and (partly) mixed in the car on holidays.
After a bit, and depending on the level of lockdown we'd have guests around to visit and when that was happening, we kept our distance at either end of our long lounge room and used a phone camera and microphone at each end.
This new setup made it much easier to do overdubs - capture more stuff into the Model 12 and make videos each time, like on this song of mine They Say Dancing where I overdubbed guitar and bass over a live track.
They Say Dancing by Peter Sefton
So what did we learn?
Perfect is the enemy of Done. Well, we knew that, but if you've decided to release a song every week, even if you're away on a holiday, or there are other things going on then there's no time to obsess over details - you have to get better at getting a useable take quickly or you won't be able to keep going for a year or more.
Practice may not make perfect, but it's a better investment than new gear, or doing endless takes with the cameras rolling. We got better at picking a song (or deciding to write one or finish one off), playing it for a week or two and then getting the take.
Simplify! We learned that to get a good performance sometimes it was better for only one of us to play or sing, that fancy parts increased the chance of major errors, meaning yet another take. If in doubt (like my harmony singing that's always in doubt) we're learning to leave it out.
Nobody likes us! Actually we know that's not true, some of the songs get hundreds of plays on Facebook but not many people actually click the like button, maybe twenty or so. But then you run into people in the supermarket; they say "love the songs keep it up"! And there are quite a few people who listen every week on FB we just can't tell they're enjoying it. There are complex reasons for this lack of engagement - some people don't like to like things so that (they think) the evil FB can't track them. I think the default auto-play for video might be a factor too - the video starts playing, and that might not be a good time, so people skip forward to something else.
It's kind of demoralizing that it is MUCH easier to get likes with pictures of the dog.

Our spoiled covid-hound, Floki - about 18 months old. Much more likeable on the socials than our music.
YouTube definitely doesn't like us. I figured that some of the songs we sang would attract some kind of Youtube audience - we often search to see what kinds of covers of songs are out there and thought others might find us the same way, but we get almost no views on that platform. I also thought that adding some text about the gear we used might bring in some views. For example we were pretty early adopters of the Tascam Model 12. I had tried to find out what one sounded like in real life before I bought, with no success - and I thought people might drop by to hear us, but I don't think Google/YouTube is giving us any search-juice at all.
Our Favourite cover we did (and we actually agreee on this - Team Happy is NOT an ironic name) was Colour my World. We'd just got the Tascam and Gail was able to double track herself - no mucking around with computers. We had fun that night.
Colour my World - one of our fave covers to perform
And my favourite original? Well i'm very proud of All L'Amour for you with lots of words and a bi-lingual pun - I wanted to do that on the local community radio just last weekend when we were asked in, but the host Richard 'Duck' Keegan kind of mentioned the aforementioned I Called Your Name so we did that instead along with Dry Pebbles and Seventeen.
All L'Amour for you The last word on love and metaphors for love? By Peter Sefton.
Gail's fave original? I may I might, the song that snagged her the best husband in South Katoomba over 1.95m tall. And she likes the tear jerker Goodbye Mongrel dog I wrote, on which she pays some pumpin' banjo.
Goodbye Mongrel dog - a song that says goodbye to a (deceased) Mongrel dog who went by the name of Spensa.
For those of you who care, here's a roundup of the main bits of kit that work well. We've reached the point where there's actually nothing on the shopping list - we can do everything for the foreseeable future with what we have.
I have mentioned that we track using the Tascam Model 12 and the Zoom H5 - these are both great. The only drawback of the Zoom is that you can't see the screen (and thus the levels) from performance position. It also needed a better wind shield - I bought a dead-cat, shaggy thing to go over the mics that works if the wind is moderate.
When I bought the Tascam I thought it was going to be all analogue through the mixer stage like their Model 16 and Model 24, but no, it's all digital. I don't think this is an issue having used it but it was not something they made all that explicit at launch. There's a digital Zoom equivalent (the L12) which is a bit smaller, and has more headphone outputs but at the expense of having to do mode-switching to to access all the functions. I think the Tascam will be easier to use for live shows when those start happening again.
For video we just use our phones - for a while we had matching Pixel 4XLs then a Pixel 5 which drowned in a tropical stream. Yes they're waterproof, those models, but not when they have tiny cracks in the screen. No more $1000 phones for me.
Reaper is bloody marvelous software. It's cheap for non-commercial use, incredibly powerful and extensible. I have not used any other Digital Audio Workstation other than Garage Band, that comes for free on the Apple Platform but as far as I can see there's no reason for non-technophobic home producers to pay any more than the Reaper fee for something else.
Our mainstay mics are a slightly battered pair of Audio Technica AT2020s - we had these for performing live with Gail's band U4ria - everyone gathered around a condenser mic, bluegrass style. For recording we either put one at either end of the room or mount them vertically in an X/Y configuration - 90° to get stereo. They're fairly airy and have come to be a big part of our sound. We tried some other cheap things that didn't work very well, and I got a pair of Australian Rode M5 pencil condenser mics, not expensive, that I hoped might be easier to mount X/Y but we didn't like them for vocals at all, though they're great on stringed instruments. We do have an SM58 and SM57 -- gotta love a microphone with a wikipedia page -- which see occasional use as vocal mics if we want a more rock 'n roll sound, or the guest singer is more used to a close-mic. And the SM57 for guitar amps sometimes.
We tend to play our favourite acoustic instruments but when we have bass we use the Trace Elliot Elf amp which has a great compressor and a DI output (it can send a signal to the mixer/interface without going via the speaker). Sometimes we run the speaker and try not to let it bleed too much into the AT2020s, very occasionally we wear headphones for the first track and go direct so there's no bass bleed. I have done a bit of electric guitar with the Boss Katana 50 - to me it sounds good in the room that amp, but has not recorded well either via the headphone out or via an SM57. I get better results thru the bass amp. I don't have any kind of actual electric guitar tone sorted though I have seen lot of videos about how to achieve the elusive tone. Maybe one day.
One thing that I wasn't expecting to happen - I dropped the top E of my little Made in Mexico Martin OOO Jr guitar to D (you know, like Keef) some time early in 2020 and it ended up staying there. Gives some nice new chord voicings (9ths mostly) and it's the same top 4 strings as a 5 string banjo with some very easy-to-grab chords. Have started doing it to Ukuleles too, putting them in open C.
A note on the bass: Playing bass is fun (we knew that before we started) but mixing it so it can be heard on a phone speaker is a real challenge. One approach that helps is using an acoustic bass which out of a lot more high frequency than a solid body electric this also helps because you don't have to have an amp on while you're tracking it live, but you can take a direct input from a pickup (or two) AND mic the bass giving you lots of signals with different EQ to play with. I gaffa-taped a guitar humbucker into my Artist Guitars 5 string acoustic and it sounds huge.
The basic (ha!) trick I try to use for getting more high frequency for tiny speakers is to create a second track, saturate the signal with distortion and/or saturation effects to boost the upper harmonic content and then cut all the low frequency out and mix that so it can just be heard and imply the fundamental bass frequency in addition to the real bassy bass. Helps if you have some bridge pickup or under-saddle pickup in the signal if those are available and if you remember.
I also like to add some phaser effect that gives some motion in the upper frequencies - for example my Perfect Country Pop Song - too much phaser? Probably, but I can hear the bass on my phone and it bounces :). Phaser is Team Happy's favourite effect, nothing says perfect country pop (which is what we are, right?) like a phaser.
Perfect Country Pop Song - is it perfect or merely sublime? (This one has a cute puppy in it).
Everything I know about music production is from YouTube. Everything I know about song writing is from deep in my soul. Thank you for reading all the way to the bottom. Normal service will resume next week.
2021-04-07T22:00:00+00:00 ptsefton Lucidworks: Let Fusion Handle Search to Get the Most Out of SharePoint https://lucidworks.com/post/lucidworks-fusion-augments-sharepoint-capabilities-for-best-knowledge-management-experience/Augment Sharepoint with a flexible search platform to deliver the best knowledge management experience in the market.
The post Let Fusion Handle Search to Get the Most Out of SharePoint appeared first on Lucidworks.
2021-04-07T15:54:54+00:00 Jenny Gomez Jez Cope: Collaborations Workshop 2021: collaborative ideas & hackday https://erambler.co.uk/blog/collabw21-part-2/My last post covered the more “traditional” lectures-and-panel-sessions approach of the first half of the SSI Collaborations Workshop. The rest of the workshop was much more interactive, consisting of a discussion session, a Collaborative Ideas session, and a whole-day hackathon!
The discussion session on day one had us choose a topic (from a list of topics proposed leading up to the workshop) and join a breakout room for that topic with the aim of producing a “speed blog” by then end of 90 minutes. Those speed blogs will be published on the SSI blog over the coming weeks, so I won’t go into that in more detail.
The Collaborative Ideas session is a way of generating hackday ideas, by putting people together at random into small groups to each raise a topic of interest to them before discussing and coming up with a combined idea for a hackday project. Because of the serendipitous nature of the groupings, it’s a really good way of generating new ideas from unexpected combinations of individual interests.
After that, all the ideas from the session, along with a few others proposed by various participants, were pitched as ideas for the hackday and people started to form teams. Not every idea pitched gets worked on during the hackday, but in the end 9 teams of roughly equal size formed to spend the third day working together.
There’s a lot of FOMO around choosing which team to join for an event like this: there were so many good ideas and I wanted to work on several of them! In the end I settled on a team developing an escape room concept to help Arts & Humanities scholars understand the benefits of working with research software engineers for their research.
Five of us rapidly mapped out an example storyline for an escape room, got a website set up with GitHub and populated it with the first few stages of the game. We decided to focus on a story that would help the reader get to grips with what an API is and I’m amazed how much we managed to get done in less than a day’s work!
You can try playing through the escape room (so far) yourself on the web, or take a look at the GitHub repository, which contains the source of the website along with a list of outstanding tasks to work on if you’re interested in contributing.
I’m not sure yet whether this project has enough momentum to keep going, but it was a really valuable way both of getting to know and building trust with some new people and demonstrating the concept is worth more work.
Here’s a brief rundown of the other projects worked on by teams on the day.
I’m excited to see so many metadata-related projects! I plan to take a closer look at what the Habeas Corpus, Credit-all and howDescribedIs teams did when I get time. I also really want to try running a dugnad with my team or for the GLAM Data Science network.
2021-04-07T15:24:10+00:00 Journal of Web Librarianship: Meeting a Higher Standard: A Case Study of Accessibility Compliance in LibGuides upon the Adoption of WCAG 2.0 Guidelines https://www.tandfonline.com/doi/full/10.1080/19322909.2021.1907267?ai=1dl&mi=co84bk&af=R .
This post was originally published on Medium but I spent time writing it so I wanted to have it here too.
TL;DR twarc has been redesigned from the ground up to work with the new Twitter v2 API and their Academic Research track. Many thanks for the code and design contributions of Betsy Alpert, Igor Brigadir, Sam Hames, Jeff Sauer, and Daniel Verdeer that have made twarc2 possible, as well as early feedback from Dan Kerchner, Shane Lin, Miles McCain, 李荣蓬, David Thiel, Melanie Walsh and Laura Wrubel. Extra special thanks to the Institute for Future Environments at Queensland University of Technology for supporting Betsy and Sam in their work, and for the continued support of the Mellon Foundation.
Back in August of last year Twitter announced early access to their new v2 API, and their plans to sunset the v1.1 API that has been active for almost the last 10 years. Over the lifetime of their v1.1 API Twitter has become deeply embedded in the media landscape. As magazines, newspapers and television have moved onto the web they have increasingly adopted tweets as a mechanism for citing politicians, celebrities and organizations, while also using them to document current events, generate leads and gather feedback for evolving stories. As a result Twitter has also become a popular object of study for humanities and social science researchers looking to understand the world as reflected, refracted and distorted by/in social media.
On the surface the v2 API update seems pretty insignificant since the shape of a tweet, its parts, properties and affordances, aren’t changing at all. Tweets with 280 characters of text, images and video will continue to be posted, retweeted and quoted. However behind the scenes the representation of a tweet as data, and the quotas that control the rates at which this data can flow between apps and other third party services will be greatly transformed.
Needless to say, v2 represents a big change for the Documenting the Now project. Along with community members we’ve developed and maintained open source tools like twarc that talk directly to the Twitter API to help users to search for and collect live tweets that match criteria like hashtags, names and geographic locations. Today we’re excited to announce the release of twarc v2 which has been designed from the ground up to work with the v2 API and Twitter’s new Academic Research track.
Clearly it’s extremely problematic having a multi-national corporation act as a gatekeeper for who counts as an academic researcher, and what constitutes academic research. We need look no further than the recent experiences of Timnit Gebru and Margaret Mitchell at Google for an example of what happens when research questions run up against the business objectives of capital. We only know their stories because Gebru and Mitchell’s bravely took a principled approach, where many researchers would have knowingly or unknowingly shaped their research to better fit the needs of the company.
So it is important for us that twarc still be usable by people with and without access to the Academic Research Track. But we have heard from many users that the Academic Research Track presents new opportunities for Twitter data collection that are essential for researchers interested in the observability of social media platforms. Twitter is making a good faith effort to work with the academic research community, and we thought twarc should support it, even if big challenges lie ahead.
So why are people interested in the Academic Research Track? Once your application has been approved you are able to collect data from the full history of Tweets, at no cost. This is a massive improvement over the v1.1 access which was limited to a one week window and researchers had to pay for access. Access to the full archive means it’s now possible to study events that have happened in the past back to the beginning of Twitter in 2006. If you do create any historical datasets we’d love for you to share the tweet identifier datasets in The Catalog.
However this opening up of access on the one hand comes with a simultaneous contraction in terms of how much data can be collected at one time. The remainder of this post describes some of the details and the design decisions we have made with twarc2 to address them. If you would prefer to watch a quick introduction to using twarc v2 please check out this short video:
If you are familiar with installing twarc nothing is changed. You still install (or upgrade) with pip as you did before:
$ pip install --upgrade twarcIn fact you will still have full access to the v1.1 API just as you did before. So the old commands will continue to work as they did1
$ twarc search blacklivesmatter > tweets.jsonltwarc2 was designed to let you to continue to use Twitter’s v1.1 API undisturbed until it is finally turned off by Twitter, at which point the functionality will be removed from twarc. All the support for the v2 API is mediated by a new command line utility twarc2. For example to search for blacklivesmatter tweets and write them to a file tweets.jsonl:
$ twarc2 search blacklivesmatter > tweets.jsonlAll the usual twarc functionality such as searching for tweets, collecting live tweets from the streaming API endpoint, requesting user timelines and user metadata are all still there, twarc2 --help gives you the details. But while the interface looks the same there’s quite a bit different going on behind the scenes.
Truth be told, there is no shortage of open source libraries and tools for interacting with the Twitter API. In the past twarc has made a bit of a name for itself by catering to a niche group of users who want a reliable, programmable way to collect the canonical JSON representation of a tweet. JavaScript Object Notation (JSON) is the language of Web APIs, and Twitter has kept its JSON representation of a tweet relatively stable over the years. Rather than making lots of decisions about the many ways you might want to collect, model and analyze tweets twarc has tried to do one thing and do it well (data collection) and get out of the way so that you can use (or create) the tools for putting this data to use.
But the JSON representation of a tweet in the Twitter v2 API is completely burst apart. The v2 base representation of a tweet is extremely lean and minimal, and just includes the text of the tweet its identifier and a handful of other things. All the details about the user who created the tweet, embedded media, and more are not included. Fortunately this information is still available, but the user needs to craft their API request to request tweets using a set of expansions that tell the Twitter API what additional entities to include. In addition for each expansion there are a set of field options to include that control what of these expansions is returned.
So rather than there being a single JSON representation of a tweet API users now have the ability to shape the data based on what they need, much like how GraphQL APIs work. This kind of makes you wonder why Twitter didn’t make their GraphQL API available. For specific use cases this customizability is very useful, but the mutability of the representation of a tweet presents challenges when collecting data for future use. If you didn’t request the right expansions or fields when collecting the data then you won’t be able to analyze that data later when doing your research.
To solve for this twarc2 has been designed to collect the richest possible representation for a tweet, by requesting all possible expansions and field combinations for tweets. See the expansions module for the details if you are interested. This takes a significant burden off of users to digest the API documentation, and craft the correct API requests themselves. In addition the twarc community will be monitoring the Twitter API documentation going forward to incorporate new expansions and fields as they will inevitably be added in the future.
This is diving into the weeds a little bit, but it’s worth noting here that Twitter’s introduction of expansions allows data that was once duplicated across multiple tweets (such as user information, media, retweets, etc) to be included once per response from the API. This means that instead of seeing information about the user who created a tweet in the context of their tweet the user will be referenced using an identifier, and this identifier will map to user metadata in the outer envelope of the response.
It makes sense why Twitter have introduced expansions since it means in a set of 100 tweets from a given user the user information will just be included once rather than repeated 100 times, which means less data, less network traffic and less money. It’s even more significant when consider the large number of possible expansions. However this pass by-reference rather than by-value presents some challenges for stream based processing which expects each tweet to be self-contained.
For this reason we’ve introduce the idea of flattening the response data when persisting the JSON to disk. This means that tools and data pipelines that expect to operate on a stream of tweets can continue to do so. Since the representation of a tweet is so dependent on how data is requested we’ve taken the opportunity to introduce a small stanza of twarc specific metadata using the __twarc prefix.
This metadata records what API endpoint the data was requested from, and when. This information is critically important when interpreting the data, because some information about a tweet like its retweet and quote counts are constantly changing.
As mentioned above you can still collect tweets from the search and streaming API endpoints in a way that seems quite similar to the v1 API. The big changes however are the quotas associated with these endpoints which govern how much can be collected. These quotas control how many requests can be sent to Twitter in 15 minute intervals.
In fact these quotas are not much changed, but what’s new are app wide quotas that constrain how many tweets a given application (app) can collect every month. An app in this context is a piece of software (e.g. your twarc software) identified by unique API keys set up in the Twitter Developer Portal. The standard API access sets a 500,000 tweet per month limit. This is a huge change considering there were no monthly app limits before. If you get approved for the Academic Research track your app quota is increased to 10 million per month. This is markedly better but the achievable data volume is still nothing like the v1.1 API, as these graphs attempt to illustrate:


twarc2 will still observe the same rate limits, but once you’ve collected your portion for the month there’s not much that can be done, for that app at least.
Apart from the quotas Twitter’s streaming endpoint in v2 is substantially changed which impacts how users interact with twarc. Previously twarc users would be able to create up to to two connections to the filter stream API. This could be done by simply:
twarc filter obama > obama.jsonlHowever in the Twitter v2 API only apps can connect to the filter stream, and they can only connect once. At first this seems like a major limitation but rather than creating a connection per query the v2 API allows you to build a set of rules for tweets to match, which in turns controls what tweets are included in the stream. This means you can collect for multiple types of queries at the same time, and the tweets will come back with a piece of metadata indicating what rule caused its inclusion.
This translates into a markedly different set of interactions at the command line for collecting from the stream where you first need to set your stream rules and then open a connection to fetch it.
twarc2 stream-rules add blacklivesmatter
twarc2 stream > tweets.jsonlOne useful side effect of this is that you can update the stream (add and remove rules) while the stream is in motion:
twarc2 stream-rules add blmWhile you are limited by the API quota in terms of how many tweets you can collect, tweets are not “dropped on the floor” when the volume gets too high. Once upon a time the v1.1 filter stream was rumored to be rate limited when your stream exceeds 1% of the total volume of new tweets.
In addition to twarc helping you collect tweets the GitHub repository has also been a place to collect a set of utilities for working with the data. For example there are scripts for extracting and unshortening urls, identifying suspended/deleted content, extracting videos, buiding wordclouds, putting tweets on maps, displaying network graph visualizations, counting hashtags, and more. These utilities all work like Unix filters where the input is a stream of tweets and the output varies depending on what the utility is doing, e.g. a Gephi file for a network visualization, or a folder of mp4 files for video extraction.
While this has worked well in general the kitchen sink approach has been difficult to manage from a configuration management perspective. Users have to download these scripts manually from GitHub or by cloning the repository. For some users this is fine, but it’s a bit of a barrier to entry for users who have just installed twarc with pip.
Furthermore these plugins often have their own dependencies which twarc itself does not. This lets twarc can stay pretty lean, and things like youtube_dl, NetworkX or Pandas can be installed by people that want to use utilities that need them. But since there is no way to install the utilities there isn’t a way to ensure that the dependencies are installed, which can lead to users needing to diagnose missing libraries themselves.
Finally the plugins have typically lacked their own tests. twarc’s test suite has really helped us track changes to the Twitter API and to make sure that it continues to operate properly as new functionality has been added. But nothing like this has existed for the utilities. We’ve noticed that over time some of them need updating. Also their command line arguments have drifted over time which can lead to some inconsistencies in how they are used.
So with twarc2 we’ve introduced the idea of plugins which extend the functionality of the twarc2 command, are distributed on PyPI separately from twarc, and exist in their own GitHub repositories where they can be developed and tested independently of twarc itself. This is all achieved through twarc2’s use of the click library and specifically click-plugins. So now if you would like to convert your collected tweets to CSV you can install the twarc-csv:
$ pip install twarc-csv
$ twarc2 search covid19 > covid19.jsonl
$ twarc2 csv covid19.jsonl > covid19.csvOr if you want to extract embedded and referenced videos from tweets you can install twarc-videos which will write all the videos to a directory:
$ pip install twarc-videos
$ twarc2 videos covid19.jsonl --download-dir covid19-videosYou can write these plugins yourself and release them as needed. Check out the plugin reference implementation tweet-ids for a simple example to adapt. We’re still in the process of porting some of the most useful utilities over and would love to see ideas for new plugins. Check out the current list of twarc2 plugins and use the twarc issue tracker on GitHub to join the discussion.
You may notice from the list of plugins that twarc now (finally) has documentation on ReadTheDocs external from the documentation that was previously only available on GitHub. We got by with GitHub’s rendering of Markdown documents for a while, but GitHub’s boilerplate designed for developers can prove to be quite confusing for users who aren’t used to selectively ignoring it. ReadTheDocs allows us to manage the command line and API documentation for twarc, and to showcase the work that has gone into the Spanish, Japanese, Portuguese, Swedish, Swahili and Chinese translations.
Thanks for reading this far! We hope you will give twarc2 a try. Let us know what you think either in comments here, in the DocNow Slack or over on GitHub.
✨ ✨ Happy twarcing! ✨ ✨ ✨
I have been working with my colleague Marco La Rosa on summary diagrams that capture some important aspects of Research Data Management, and include the FAIR data principles; that data should be Findable, Accessible, Interoperable and Reusable.
But first, here's a rant about some modeling and diagramming styles and trends that I do not like.
I took part in a fun Twitter thread recently kicked off by Fiona Tweedie.
Fiona Tweedie @FCTweedie So my current bugbear is university processes that seem to forget that the actual work of higher ed is doing research and/ or teaching. This "research lifecycle" diagram from @UW is a stunning example:
In this tweet Dr Tweedie has called out Yet Another Research Lifecycle Diagram That Leaves Out The Process Of You Know, Actually Doing Research. This process-elision happened more than once when I was working as an eResearch manager - management would get in the consultants to look at research systems, talk to the research office and graduate school and come up with a "journey map" of administrative processes that either didn't mention the actual DOING research or represented it as a tiny segment, never mind that it's, you know, the main thing researchers do when they're being researchers rather than teachers or administrators.
At least the consultants would usually produce a 'journey map' that got you from point A to Point B using chevrons to >> indicate progress and didn't insist that everything was a 'lifecycle'.
Something like:
Plan / Propose >> Setup >> Manage / Do Research >> Closeout
But all too commonly processes are represented using the tired old metaphor of a lifecycle.
Reminder: A lifecycle is a biological process; how organisms come into existence, reproduce and die via various means including producing seeds, splitting themselves in two, um, making love, laying eggs and so on.
It's really stretching the metaphor to talk about research in this way - maybe the research outputs in the UW "closeout" phase are eggs that hatch into new bouncing baby proposals?
Regrettably, arranging things in circles and using the "lifecycle" metaphor is very common - see this Google image search for "Research Lifecycle":
I wonder if the diagramming tools that are available to people are part of the issue - Microsoft Word, for example can build cycles and other diagrams out of a bullet list.
(I thought it would be amusing to draw the UW diagram from above as a set cogs but this happened - you can only have 3 cogs in a Word diagram.)
Now that I've got that off my chest let's look at research data management. Here's a diagram which is in fairly wide use, from The University of California.
(This image has a CC-BY logo which means I can use it if I attribute it - but I'm not 100% clear on the original source of the diagram - it seems to be from UC somewhere.)
Marco used this one in some presentations we gave. I thought we could do better.
The good part of this diagram is that it shows research data management as a cyclical, recurring activity - which for FAIR data it needs to be.
What I don't like:
I think it is trying to show a project (ie grant) level view of research with data management happening in ONE spot on the journey. Typically researchers do research all the time (or in between teaching or when they can get time on equipment) not at a particular point in some administrative "journey map". We often hear feedback that their research is a lifetime activity and does not happen the way administrators and IT think it does.
"Archive" is shown as a single-step pre-publication. This is a terrible message; if we are to start really doing FAIR data then data need to be described and made findable and accessible ASAP.
The big so-called lifecycle is (to me) very contrived and looks like a librarian view of the world with data searching as a stand-alone process before research data management planning. Not clear whether Publication means articles or data.
"Data Search / Reuse" is a type of "Collection", and why is it happening before data management planning? "Re-Collection" is also a kind of collection, so we can probably collapse all those together (the Findable and Accessible in FAIR).
It’s not clear whether Publication means articles or data or both.
Most research uses some kind of data storage but very often not directly; people might be interacting with a lab notebook system or a data repository - at UTS we arrived at the concept of "workspaces" to capture this.
Marco and I have a sketch of a new diagram that attempts to address these issues and addresses what needs to be in place for broad-scale FAIR data practice.
Two of the FAIR principles suggest services that need to be in place; ways to Find and Access data. The I and R in FAIR are not something that can be encapsulated in a service, as such, rather they imply that data are well described for re-use and Interoperation of systems and in Reusable formats.
As it happens, there is a common infrastructure component which encapsulates finding data and accessing; the repository. Repositories are services which hold data and make it discoverable and accessible, with governance that ensures that data does not change without notice and is available for access over agreed time frames - sometimes with detailed access control. Repositories may be general purpose or specialized around a particular type of data: gene sequences, maps, code, microscope images etc. They may also be ad-hoc - at a lab level they could be a well laid out, well managed file system.
Some well-funded disciplines have established global or national repositories and workflows for some or all of their data, notably physics and astronomy, bioinformatics, geophysical sciences, climate and marine science. Some of these may not be thought of by their community as repositories - but according to our functional definition they are repositories, even if they are "just" vast shared file systems or databases where everyone knows what's what and data managers keep stuff organized. Also, some institutions have institutional data repositories but it is by no means common practice across the whole of the research sector that data find their way into any of these repositories.
Remember: data storage is not all files-on-disks. Researchers use a very wide range of tools which may make data inaccessible outside of the tool. Examples include: cloud-based research (lab) notebook systems in which data is deposited alongside narrative activity logs; large shared virtual laboratories where data are uploaded; Secure eResearch Platforms (SERPs) which allow access only via virtualized desktops with severely constrained data ingress and egress; survey tools; content management systems; digital asset management systems; email (yes, it's true some folks use email as project archives!); to custom-made code for a single experiment.
Our general term for all of the infrastructures that researchers use for RDM day to day including general purpose storage is “workspaces”.
Many, if not most workspaces do not have high levels of governance, and data may be technically or legally inaccessible over the long term. They should not be considered as suitable archives or repositories - hence our emphasis on making sure that data can be described and deposited into general purpose, standards-driven repository services.
The following is a snapshot of the core parts of an idealised FAIR data service. It shows the activities that researchers undertake, acquiring data from observations, instruments and by reuse, conducting analysis and data description in a working environment, and depositing results into one or more repositories.
We wanted it to show:
That infrastructure services are required for research data management - researchers don't just "Archive" their data without support - they and those who will reuse data need repository services in some form.
That research is conducted using workspace environments - more infrastructure.
We (by which I mean Marco) will make this prettier soon.
And yes, there is a legitimate cycle in this diagram it's the FIND -> ACCESS -> REUSE -> DESCRIBE -> DEPOSIT cycle that's inherent in the FAIR lifestyle.
Things that might still be missing:
Some kind of rubbish bin - to show that workspaces are ephemeral and working data that doesn't make the cut may be culled, and that some data is held only for a time.
What do you think's missing?
Thoughts anyone? Comments below or take it up on twitter with @ptsefton.
(I have reworked parts of a document that Marco and I have been working on with Guido Aben for this document, and thanks to recent graduate Florence Sefton for picking up typos and sense-checking).
2021-04-06T22:00:00+00:00 ptsefton David Rosenthal: Elon Musk: Threat or Menace? https://blog.dshr.org/2021/04/elon-musk-threat-or-menace.html Although both Tesla and SpaceX are major engineering achievements, Elon Musk seems completely unable to understand the concept of externalities, unaccounted-for costs that society bears as a result of these achievements.Looked at differently, a single Bitcoin purchase at a price of ~$50,000 has a carbon footprint of 270 tons, the equivalent of 60 ICE cars.Below the fold, more externalities Musk is ignoring.
Tesla’s average selling price in the fourth quarter of 2020? $49,333.
We’re not sure about you, but FT Alphaville is struggling to square the circle of “buy a Tesla with a bitcoin and create the carbon output of 60 internal combustion engine cars” with its legendary environmental ambitions.
Unless, of course, that was never the point in the first place.
Suppose, for the sake of argument, that self-driving cars three times as good as Waymo's are in wide use by normal people. A normal person would encounter a hand-off once in 15,000 miles of driving, or less than once a year. Driving would be something they'd be asked to do maybe 50 times in their life.Mack Hogan's Tesla's "Full Self Driving" Beta Is Just Laughably Bad and Potentially Dangerous starts:
Even if, when the hand-off happened, the human was not "climbing into the back seat, climbing out of an open car window, and even smooching" and had full "situational awareness", they would be faced with a situation too complex for the car's software. How likely is it that they would have the skills needed to cope, when the last time they did any driving was over a year ago, and on average they've only driven 25 times in their life? Current testing of self-driving cars hands-off to drivers with more than a decade of driving experience, well over 100,000 miles of it. It bears no relationship to the hand-off problem with a mass deployment of self-driving technology.
A beta version of Tesla's "Full Self Driving" Autopilot update has begun rolling out to certain users. And man, if you thought "Full Self Driving" was even close to a reality, this video of the system in action will certainly relieve you of that notion. It is perhaps the best comprehensive video at illustrating just how morally dubious, technologically limited, and potentially dangerous Autopilot's "Full Self Driving" beta program is.Hogan sums up the lesson of the video:
Tesla's software clearly does a decent job of identifying cars, stop signs, pedestrians, bikes, traffic lights, and other basic obstacles. Yet to think this constitutes anything close to "full self-driving" is ludicrous. There's nothing wrong with having limited capabilities, but Tesla stands alone in its inability to acknowledge its own shortcomings.Hogan goes on to point out the externalities:
When technology is immature, the natural reaction is to continue working on it until it's ironed out. Tesla has opted against that strategy here, instead choosing to sell software it knows is incomplete, charging a substantial premium, and hoping that those who buy it have the nuanced, advanced understanding of its limitations—and the ability and responsibility to jump in and save it when it inevitably gets baffled. In short, every Tesla owner who purchases "Full Self-Driving" is serving as an unpaid safety supervisor, conducting research on Tesla's behalf. Perhaps more damning, the company takes no responsibility for its actions and leaves it up to driver discretion to decide when and where to test it out.Of course, the drivers are only human so they do slip up:
That leads to videos like this, where early adopters carry out uncontrolled tests on city streets, with pedestrians, cyclists, and other drivers unaware that they're part of the experiment. If even one of those Tesla drivers slips up, the consequences can be deadly.
the Tesla arrives at an intersection where it has a stop sign and cross traffic doesn't. It proceeds with two cars incoming, the first car narrowly passing the car's front bumper and the trailing car braking to avoid T-boning the Model 3. It is absolutely unbelievable and indefensible that the driver, who is supposed to be monitoring the car to ensure safe operation, did not intervene there.An example of the kinds of problems that can be caused by autonomous vehicles behaving in ways that humans don't expect is reported by Timothy B. Lee in Fender bender in Arizona illustrates Waymo’s commercialization challenge:
A white Waymo minivan was traveling westbound in the middle of three westbound lanes on Chandler Boulevard, in autonomous mode, when it unexpectedly braked for no reason. A Waymo backup driver behind the wheel at the time told Chandler police that "all of a sudden the vehicle began to stop and gave a code to the effect of 'stop recommended' and came to a sudden stop without warning."The Tesla in the video made a similar unexpected stop. Lee stresses that, unlike Tesla's, Waymo's responsible test program has resulted in a generally safe product, but not one that is safe enough:
A red Chevrolet Silverado pickup behind the vehicle swerved to the right but clipped its back panel, causing minor damage. Nobody was hurt.
Waymo has racked up more than 20 million testing miles in Arizona, California, and other states. This is far more than any human being will drive in a lifetime. Waymo's vehicles have been involved in a relatively small number of crashes. These crashes have been overwhelmingly minor with no fatalities and few if any serious injuries. Waymo says that a large majority of those crashes have been the fault of the other driver. So it's very possible that Waymo's self-driving software is significantly safer than a human driver.I'm a pedestrian, cyclist and driver in an area infested with Teslas owned, but potentially not actually being driven, by fanatical early adopters and members of the cult of Musk. I'm personally at risk from these people believing that what they paid good money for was "Full Self Driving". When SpaceX tests Starship at their Boca Chica site they take precautions, including road closures, to ensure innocent bystanders aren't at risk from the rain of debris when things go wrong. Tesla, not so much.
...
The more serious problem for Waymo is that the company can't be sure that the idiosyncrasies of its self-driving software won't contribute to a more serious crash in the future. Human drivers cause a fatality about once every 100 million miles of driving—far more miles than Waymo has tested so far. If Waymo scaled up rapidly, it would be taking a risk that an unnoticed flaw in Waymo's programming could lead to someone getting killed.
"Despite the "full self-driving" name, Tesla admitted it doesn't consider the current beta software suitable for fully driverless operation. The company said it wouldn't start testing "true autonomous features" until some unspecified point in the future.There is an urgent need for regulators to step up and stop this dangerous madness:
...
Tesla added that "we do not expect significant enhancements" that would "shift the responsibility for the entire dynamic driving task to the system." The system "will continue to be an SAE Level 2, advanced driver-assistance feature."
SAE level 2 is industry jargon for a driver-assistance systems that perform functions like lane-keeping and adaptive cruise control. By definition, level 2 systems require continual human oversight. Fully driverless systems—like the taxi service Waymo is operating in the Phoenix area—are considered level 4 systems."
I’ve just finished attending (online) the three days of this year’s SSI Collaborations Workshop (CW for short), and once again it’s been a brilliant experience, as well as mentally exhausting, so I thought I’d better get a summary down while it’s still fresh it my mind.
Collaborations Workshop is, as the name suggests, much more focused on facilitating collaborations than a typical conference, and has settled into a structure that starts off with with longer keynotes and lectures, and progressively gets more interactive culminating with a hack day on the third day.
That’s a lot to write about, so for this post I’ll focus on the talks and panel session, and follow up with another post about the collaborative bits. I’ll also probably need to come back and add in more links to bits and pieces once slides and the “official” summary of the event become available.
Updates
The first day began with two keynotes on this year’s main themes: FAIR Research Software and Diversity & Inclusion, and day 2 had a great panel session focused on disability. All three were streamed live and the recordings remain available on Youtube:
Dr Michelle Barker, Director of the Research Software Alliance, spoke on the challenges to recognition of software as part of the scholarly record: software is not often cited. The FAIR4RS working group has been set up to investigate and create guidance on how the FAIR Principles for data can be adapted to research software as well; as they stand, the Principles are not ideally suited to software. This work will only be the beginning though, as we will also need metrics, training, career paths and much more. ReSA itself has 3 focus areas: people, policy and infrastructure. If you’re interested in getting more involved in this, you can join the ReSA email list.
Dr Chonnettia Jones, Vice President of Research, Michael Smith Foundation for Health Research spoke extensively and persuasively on the need for Equality, Diversity & Inclusion (EDI) initiatives within research, as there is abundant robust evidence that all research outcomes are improved.
She highlighted the difficulties current approaches to EDI have effecting structural change, and changing not just individual behaviours but the cultures & practices that perpetuate iniquity. What initiatives are often constructed around making up for individual deficits, a bitter framing is to start from an understanding of individuals having equal stature but having different tired experiences. Commenting on the current focus on “research excellent” she pointed out that the hyper-competition this promotes is deeply unhealthy. suggesting instead that true excellence requires diversity, and we should focus on an inclusive excellence driven by inclusive leadership.
Day 2’s EDI panel session brought together five disabled academics to discuss the problems of disability in research.
NB. The discussion flowed quite freely so the following summary, so the following summary mixes up input from all the panel members.
Researchers are often assumed to be single-minded in following their research calling, and aptness for jobs is often partly judged on “time send”, which disadvantages any disabled person who has been forced to take a career break. On top of this disabled people are often time-poor because of the extra time needed to manage their condition, leaving them with less “output” to show for their time served on many common metrics. This can partially affect early-career researchers, since resources for these are often restricted on a “years-since-PhD” criterion. Time poverty also makes funding with short deadlines that much harder to apply for. Employers add more demands right from the start: new starters are typically expected to complete a health and safety form, generally a brief affair that will suddenly become an 80-page bureaucratic nightmare if you tick the box declaring a disability.
Many employers claim to be inclusive yet utterly fail to understand the needs of their disabled staff. Wheelchairs are liberating for those who use them (despite the awful but common phrase “wheelchair-bound”) and yet employers will refuse to insure a wheelchair while travelling for work, classifying it as a “high value personal item” that the owner would take the same responsibility for as an expensive camera. Computers open up the world for blind people in a way that was never possible without them, but it’s not unusual for mandatory training to be inaccessible to screen readers. Some of these barriers can be overcome, but doing so takes yet more time that could and should be spent on more important work.
What can we do about it? Academia works on patronage whether we like it or not, so be the person who supports people who are different to you rather than focusing on the one you “recognise yourself in” to mentor. As a manager, it’s important to ask each individual what they need and believe them: they are the expert in their own condition and their lived experience of it. Don’t assume that because someone else in your organisation with the same disability needs one set of accommodations, it’s invalid for your staff member to require something totally different. And remember: disability is unusual as a protected characteristic in that anyone can acquire it at any time without warning!
Lightning talk sessions are always tricky to summarise, and while this doesn’t do them justice, here are a few highlights from my notes.
That’s not everything! But this post is getting pretty long so I’ll wrap up for now. I’ll try to follow up soon with a summary of the “collaborative” part of Collaborations Workshop: the idea-generating sessions and hackday!
2021-04-05T20:56:09+00:00 Journal of Web Librarianship: Examination of Academic Library Websites Regarding COVID-19 Responsiveness https://www.tandfonline.com/doi/full/10.1080/19322909.2021.1906823?ai=1dl&mi=co84bk&af=R .ChangeLog: https://marcedit.reeset.net/software/update75.txt
One of the most requested features over the years has been the ability to preview changes prior to running them. As of 7.5.8 – a new preview option has been added to many of the global editing tools in the MarcEditor. Currently, you will find the preview option attached to the following functions:
Functions that include a preview option will be denoted with the following button:

When this button is pressed, the following option is made available

When Preview Results is selected, the program will execute the defined action, and display the potential results in a display screen. For example:

To protect performance, only 500 results at a time will be loaded into the preview grid, though users can keep adding results to the grid and continue to review items. Additionally, users have the ability to search for items within the grid as well as jump to a specific record number (not row number).
These new options will show up first in the windows version of MarcEdit, but will be added to the MarcEdit Mac 3.5.x branch in the coming weeks.
To better support the translation of data from JSON to MARC, I’ve included a JSON => MARC algorithm in the MARCEngine. This will allow JSON data to serialized into XML. The benefit of including this option, is that I’ve been able to update the XML Functions options to allow JSON to be a starting format. This will specifically useful for users that want to make use of linked data vocabularies to generate MARC Authority records. Users can direct MarcEdit to facilitate the translation from JSON to XML, and then create XSLT translations that can then be used to complete the process to MARCXML and MARC. I’ve demonstrated how this process works using a vocabulary of interest to the #critcat community, the Homosaurus vocabulary (How do I generate MARC authority records from the Homosaurus vocabulary? – Terry’s Worklog (reeset.net)).
Working with the OCLC API is sometimes tricky. MarcEdit utilizes a specific authentication process that requires OCLC keys be setup and configured to work a certain way. When issues come up, it is sometimes very difficult to debug them. I’ve updated the process and error handling to surface more information – so when problems occur and XML debugging information isn’t available, the actual exception and inner exception data will be surfaced instead. This often can provide information to help understand why the process isn’t able to complete.
As noted, there have been a number of updates. While many fall under the category of house-keeping (updating icons, UX improvements, actions, default values, etc.) – this update does include a number of often asked for, significant updates, that I hope will improve user workflows.
–tr
2021-04-04T02:26:28+00:00 reeset Terry Reese: How do I generate MARC authority records from the Homosaurus vocabulary? https://blog.reeset.net/archives/2953Step by step instructions here: https://youtu.be/FJsdQI3pZPQ
Ok, so last week, I got an interesting question on the listserv where a user asked specifically about generating MARC records for use in one’s ILS system from a JSONLD vocabulary. In this case, the vocabulary in question as Homosaurus (Homosaurus Vocabulary Site) – and the questioner was specifically looking for a way to pull individual terms for generation into MARC Authority records to add to one’s ILS to improve search and discovery.
When the question was first asked, my immediate thought was that this could likely be accommodated using the XML/JSON profiling wizard in MarcEdit. This tool can review a sample XML or JSON file and allow a user to create a portable processing file based on the content in the file. However, there were two issues with this approach:
While I updated the Profiler to recognize and work better with JSON-LD – the first challenge is one that doesn’t make this a good fit to create a generic process. So, I looked at how this could be built into the normal processing options.
To do this, I added a new default serialization, JSON=>XML == which MarcEdit now supports. This allows the tool to take a JSON file, and deserialize the data so that is output reliably as XML. So, for example, here is a sample JSON-LD file (homosaurus.org/v2/adoptiveParents.jsonld):
{
"@context": {
"dc": "http://purl.org/dc/terms/",
"skos": "http://www.w3.org/2004/02/skos/core#",
"xsd": "http://www.w3.org/2001/XMLSchema#"
},
"@id": "http://homosaurus.org/v2/adoptiveParents",
"@type": "skos:Concept",
"dc:identifier": "adoptiveParents",
"dc:issued": {
"@value": "2019-05-14",
"@type": "xsd:date"
},
"dc:modified": {
"@value": "2019-05-14",
"@type": "xsd:date"
},
"skos:broader": {
"@id": "http://homosaurus.org/v2/parentsLGBTQ"
},
"skos:hasTopConcept": [
{
"@id": "http://homosaurus.org/v2/familyMembers"
},
{
"@id": "http://homosaurus.org/v2/familiesLGBTQ"
}
],
"skos:inScheme": {
"@id": "http://homosaurus.org/terms"
},
"skos:prefLabel": "Adoptive parents",
"skos:related": [
{
"@id": "http://homosaurus.org/v2/socialParenthood"
},
{
"@id": "http://homosaurus.org/v2/LGBTQAdoption"
},
{
"@id": "http://homosaurus.org/v2/LGBTQAdoptiveParents"
},
{
"@id": "http://homosaurus.org/v2/birthParents"
}
]
}
In MarcEdit, the new JSON=>XML process can take this file and output it in XML like this:
<?xml version="1.0"?>
<records>
<record>
<context>
<dc>http://purl.org/dc/terms/</dc>
<skos>http://www.w3.org/2004/02/skos/core#</skos>
<xsd>http://www.w3.org/2001/XMLSchema#</xsd>
</context>
<id>http://homosaurus.org/v2/adoptiveParents</id>
<type>skos:Concept</type>
<identifier>adoptiveParents</identifier>
<issued>
<value>2019-05-14</value>
<type>xsd:date</type>
</issued>
<modified>
<value>2019-05-14</value>
<type>xsd:date</type>
</modified>
<broader>
<id>http://homosaurus.org/v2/parentsLGBTQ</id>
</broader>
<hasTopConcept>
<id>http://homosaurus.org/v2/familyMembers</id>
</hasTopConcept>
<hasTopConcept>
<id>http://homosaurus.org/v2/familiesLGBTQ</id>
</hasTopConcept>
<inScheme>
<id>http://homosaurus.org/terms</id>
</inScheme>
<prefLabel>Adoptive parents</prefLabel>
<related>
<id>http://homosaurus.org/v2/socialParenthood</id>
</related>
<related>
<id>http://homosaurus.org/v2/LGBTQAdoption</id>
</related>
<related>
<id>http://homosaurus.org/v2/LGBTQAdoptiveParents</id>
</related>
<related>
<id>http://homosaurus.org/v2/birthParents</id>
</related>
</record>
</records>
The ability to reliably convert JSON/JSONLD to XML means that I can now allow users to utilize the same XSLT/XQUERY process MarcEdit utilizes for other library metadata format transformation. All that was left to make this happen was to add a new origin data format to the XML Function template – and we are off and running.
The end result is users could utilize this process with any JSON-LD vocabulary (assuming they created the XSLT) to facilitate the automation of MARC Authority data. In this case of this vocabulary, I’ve created an XSLT and added it to my github space: https://github.com/reeset/marcedit_xslt_files/blob/master/homosaurus_xml.xsl
but have included the XSLT in the MarcEdit XSLT directory in current downloads.
In order to use this XSLT and allow your version of MarcEdit to generate MARC Authority records from this vocabulary – you would use the following steps:
That should be pretty much it. I’ve recorded the steps and placed them here: https://youtu.be/FJsdQI3pZPQ, including some information on values you may wish to edit should you want to localize the XSLT.
2021-04-04T02:25:19+00:00 reeset Peter Murray: Publishers going-it-alone (for now?) with GetFTR https://dltj.org/article/publishers-alone-with-getftr/In early December 2019, a group of publishers announced Get-Full-Text-Research, or GetFTR for short. I read about this first in Roger Schonfeld’s “Publishers Announce a Major New Service to Plug Leakage” piece in The Scholarly Kitchen via Jeff Pooley’s Twitter thread and blog post. Details about how this works are thin, so I’m leaning heavily on Roger’s description. I’m not as negative about this as Jeff, and I’m probably a little more opinionated than Roger. This is an interesting move by publishers, and—as the title of this post suggests—I am critical of the publisher’s “go-it-alone” approach.
First, some disclosure might be in order. My background has me thinking of this in the context of how it impacts libraries and library consortia. For the past four years, I’ve been co-chair of the NISO Information Discovery and Interchange topic committee (and its predecessor, the “Discovery to Delivery” topic committee), so this is squarely in what I’ve been thinking about in the broader library-publisher professional space. I also traced the early development of RA21 and more recently am volunteering on the SeamlessAccess Entity Category and Attribute Bundles Working Group; that’ll become more important a little further down this post.
I was nodding along with Roger’s narrative until I stopped short here:
The five major publishing houses that are the driving forces behind GetFTR are not pursuing this initiative through one of the major industry collaborative bodies. All five are leading members of the STM Association, NISO, ORCID, Crossref, and CHORUS, to name several major industry groups. But rather than working through one of these existing groups, the houses plan instead to launch a new legal entity.
While [Vice President of Product Strategy & Partnerships for Wiley Todd] Toler and [Senior Director, Technology Strategy & Partnerships for the American Chemical Society Ralph] Youngen were too politic to go deeply into the details of why this might be, it is clear that the leadership of the large houses have felt a major sense of mismatch between their business priorities on the one hand and the capabilities of these existing industry bodies. At recent industry events, publishing house CEOs have voiced extensive concerns about the lack of cooperation-driven innovation in the sector. For example, Judy Verses from Wiley spoke to this issue in spring 2018, and several executives did so at Frankfurt this fall. In both cases, long standing members of the scholarly publishing sector questioned if these executives perhaps did not realize the extensive collaborations driven through Crossref and ORCID, among others. It is now clear to me that the issue is not a lack of knowledge but rather a concern at the executive level about the perceived inability of existing collaborative vehicles to enable the new strategic directions that publishers feel they must pursue.
This is the publishers going-it-alone. To see Roger describe it, they are going to create this web service that allows publishers to determine the appropriate copy for a patron and do it without input from the libraries. Librarians will just be expected to put this web service widget into their discovery services to get “colored buttons indicating that the link will take [patrons] to the version of record, an alternative pathway, or (presumably in rare cases) no access at all.” (Let’s set aside for the moment the privacy implications of having a fourth-party web service recording all of the individual articles that come up in a patron’s search results.) Librarians will not get to decide the “alternative pathway” that is appropriate for the patron: “Some publishers might choose to provide access to a preprint or a read-only version, perhaps in some cases on some kind of metered basis.” (Roger goes on to say that he “expect[s] publishers will typically enable some alternative version for their content, in which case the vast majority of scholarly content will be freely available through publishers even if it is not open access in terms of licensing.” I’m not so confident.)
No, thank you. If publishers want to engage in technical work to enable libraries and others to build web services that determine the direct link to an article based on a DOI, then great. Libraries can build a tool that consumes that information as well as takes into account information about preprint services, open access versions, interlibrary loan and other methods of access. But to ask libraries to accept this publisher-controlled access button in their discovery layers, their learning management systems, their scholarly profile services, and their other tools? That sounds destined for disappointment.
I am only somewhat encouraged by the fact that RA21 started out as a small, isolated collaboration of publishers before they brought in NISO and invited libraries to join the discussion. Did it mean that it slowed down deployment of RA21? Undoubtedly yes. Did persnickety librarians demand transparent discussions and decisions about privacy-related concerns like what attributes the publisher would get about the patron in the Shibboleth-powered backchannel? Yes, but because the patrons weren’t there to advocate for themselves. Will it likely mean wider adoption? I’d like to think so.
Have publishers learned that forcing these kinds of technologies onto users without consultation is a bad idea? At the moment it would appear not. Some of what publishers are seeking with GetFTR can be implemented with straight-up OpenURL or—at the very least—limited-scope additions to OpenURL (the Z39.88 open standard!). So that they didn’t start with OpenURL, a robust existing standard, is both concerning and annoying. I’ll be watching and listening for points of engagement, so I remain hopeful.
A few words about Jeff Pooley’s five-step “laughably creaky and friction-filled effort” that is SeamlessAccess. Many of the steps Jeff describes are invisible and well-established technical protocols. What Jeff fails to take into account is the very visible and friction-filled effect of patrons accessing content beyond the boundaries of campus-recognized internet network addresses. Those patrons get stopped at step two with a “pay $35 please” message. I’m all for removing that barrier entirely by making all published content “open access”. It is folly to think, though, that researchers and readers can enforce an open access business model on all publishers, so solutions like SeamlessAccess will have a place. (Which is to say nothing of the benefit of inter-institutional resource collaboration opened up by a more widely deployed Shibboleth infrastructure powered by SeamlessAccess.)
In early December 2019, a group of publishers announced Get-Full-Text-Research, or GetFTR for short. There was a heck of a response on social media, and the response was—on the whole—not positive from my librarian-dominated corner of Twitter. For my early take on GetFTR, see my December 3rd blog post “Publishers going-it-alone (for now?) with GetFTR.” As that post title suggests, I took the five founding GetFTR publishers to task on their take-it-or-leave-it approach. I think that is still a problem. To get you caught up, here is a list of other commentary.
If you are looking for a short list of what to look at, I recommend these posts.
On December 11—after the two posts I list below—an “Updating the Community” web page was posted to the GetFTR website. From a public relations perspective, it was…interesting.
This section goes on to say, “If the community feels we need to add librarians to our advisory group we will certainly do so and we will explore ways to ensure we engage with as many of our librarian stakeholders as possible.” If the GetFTR leadership didn’t get the indication between December 3 and December 12 that librarians feel strongly about being at the table, then I don’t know what will. And it isn’t about being on the advisory group; it is about being seen and appreciated as important stakeholders in the research discovery process. I’m not sure who the “community” is in this section, but it is clear that librarians are—at best—an afterthought. That is not the kind of “open and transparent” that is welcoming.
Later on in the Questions about library link resolvers section is this sentence:
We have, or are planning to, consult with existing library advisory boards that participating publishers have, as this enables us to gather views from a significant number of librarians from all over the globe, at a range of different institutions.
As I said in my previous post, I don’t know why GetFTR is not engaging in existing cross-community (publisher/technology-supplier/library) organizations to have this discussion. It feels intentional, which colors the perception of what the publishers are trying to accomplish. To be honest, I don’t think the publishers are using GetFTR to drive a wedge between library technology service providers (who are needed to make GetFTR a reality for libraries) and libraries themselves. But I can see how that interpretation could be made.
I punted on privacy in my previous post, so let’s talk about it here. It remains to be seen what is included in the GetFTR API request between the browser and the publisher site. Sure, it needs to include the DOI and a token that identifies the patron’s institution. We can inspect that API request to ensure nothing else is included. But the fact that the design of GetFTR has the browser making the call to the publisher site means that the publisher site knows the IP address of the patron’s browser, and the IP address can be considered personally identifiable information. This issue could be fixed by having the link resolver or the discovery layer software make the API request, and according to the Questions about library link resolvers section of the community update, this may be under consideration.
So, yes, an auditable privacy policy and implementation is key for for GetFTR.
This is good to hear. I would love to see more information published about this, including how discipline-specific repositories and institutional repositories can have their holdings represented in GetFTR responses.
In the second to last paragraph: “Researchers should have easy, seamless pathways to research, on whatever platform they are using, wherever they are.” That is a statement that I think every library could sign onto. This Updating the Community is a good start, but the project has dug a deep hole of trust and it hasn’t reached level ground yet.
Posted on December 10th in The Scholarly Kitchen, Lisa outlines a series of concerns from a librarian perspective. I agree with some of these; others are not an issue in my opinion.
Many librarians have expressed a concern about how patron information can leak to the publisher through ill-considered settings at an institution’s identity provider. Seamless Access can ease access control because it leverages a campus’ single sign-on solution—something that a library patron is likely to be familiar with. If the institution’s identity provider is overly permissive in the attributes about a patron that get transmitted to the publisher, then there is a serious risk of tying a user’s research activity to their identity and the bad things that come from that (patrons self-censoring their research paths, commoditization of patron activity, etc.). I’m serving on a Seamless Access task force that is addressing this issue, and I think there are technical, policy, and education solutions to this concern. In particular, I think some sort of intermediate display of the attributes being transmitted to the publisher is most appropriate.
As Lisa points out, the population of institutions that can take advantage of Seamless Access, a prerequisite for GetFTR, is very small and weighted heavily towards well-resourced institutions. To the extent that projects like Seamless Access (spurred on by a desire to have GetFTR-like functionality) helps with the adoption of SAML-based infrastructure like Shibboleth, then the whole academic community benefits from a shared authentication/identity layer that can be assumed to exist.
Of the issues Lisa mentioned here, I’m not concerned about users being redirected to their campus single sign-on system in multiple browsers on multiple machines. This is something we should be training users about—there is a single website to put your username/password into for whatever you are accessing at the institution. That a user might already be logged into the institution single sign-on system in the course of doing other school work and never see a logon screen is an attractive benefit to this system.
That said, it would be useful for an API call from a library’s discovery layer to a publisher’s GetFTR endpoint to be able to say, “This is my user. Trust me when I say that they are from this institution.” If that were possible, then the Seamless Access Where-Are-You-From service could be bypassed for the GetFTR purpose of determining whether a user’s institution has access to an article on the publisher’s site. It would sure be nice if librarians were involved in the specification of the underlying protocols early on so these use cases could be offered.
Lisa reached out on Twitter to say (in part): “Issue is GetFTR doesn’t redirect and SA doesnt when you are IPauthenticated. Hence user ends up w mishmash of experience.” I went back to read her Scholarly Kitchen post and realized I did not fully understand her point. If GetFTR is relying on a Seamless Access token to know which institution a user is coming from, then that token must get into the user’s browser. The details we have seen about GetFTR don’t address how that Seamless Access institution token is put in the user’s browser if the user has not been to the Seamless Access select-your-institution portal. One such case is when the user is coming from an IP-address-authenticated computer on a campus network. Do the GetFTR indicators appear even when the Seamless Access institution token is not stored in the browser? If at the publisher site the GetFTR response also uses the institution IP address table to determine entitlements, what does a user see when they have neither the Seamless Access institution token nor the institution IP address? And, to Lisa’s point, how does one explain this disparity to users? Is the situation better if the GetFTR determination is made in the link resolver rather than in the user browser?
See previous paragraph. That librarians are not at the table offering use cases and technical advice means that the developers are likely closing off options that meet library needs. Addressing those needs would ease the acceptance of the GetFTR project as mutually beneficial. So an emphatic “AGREE!” with Lisa on her points in this section. Publishers—what were you thinking?
Libraries and library technology companies are making significant investments in tools that ease the path from discovery to delivery. Would the library’s link resolver benefit from a real-time API call to a publisher’s service that determines the direct URL to a specific DOI? Oh, yes—that would be mighty beneficial. The library could put that link right at the top of a series of options that include a link to a version of the article in a Green Open Access repository, redirection to a content aggregator, one-click access to an interlibrary-loan form, or even an option where the library purchases a copy of the article on behalf of the patron. (More likely, the link resolver would take the patron right to the article URL supplied by GetFTR, but the library link resolver needs to be in the loop to be able to offer the other options.)
The patron is affiliated with the institution, and the institution (through the library) is subscribing to services from the publisher. The institution’s library knows best what options are available to the patron (see above section). Want to know why librarians are concerned? Because they are inserting themselves as the arbiter of access to content, whether it is in the patron’s best interest or not. It is also useful to reinforce Lisa’s closing paragraph:
Whether GetFTR will act to remediate these concerns remains to be seen. In some cases, I would expect that they will. In others, they may not. Publishers’ interests are not always aligned with library interests and they may accept a fraying relationship with the library community as the price to pay to pursue their strategic goals.
Ian’s entire post from December 11th in ScholCommsProd is worth reading. I think it is an insightful look at the technology and its implications. Here are some specific comments:
There are a couple of things that I disagree with:
OK, so what is the difference, for the user, between seamlessaccess and GetFTR? I think that the difference is the following - with seamless access you the user have to log in to the publisher site. With GetFTR if you are providing pages that contain DOIs (like on a discovery service) to your researchers, you can give them links they can click on that have been setup to get those users direct access to the content. That means as a researcher, so long as the discovery service has you as an authenticated user, you don’t need to even think about logins, or publisher access credentials.
To the best of my understanding, this is incorrect. With SeamlessAccess, the user is not “logging into the publisher site.” If the publisher site doesn’t know who a user is, the user is bounced back to their institution’s single sign-on service to authenticate. If the publisher site doesn’t know where a user is from, it invokes the SeamlessAccess Where-Are-You-From service to learn which institution’s single sign-on service is appropriate for the user. If a user follows a GetFTR-supplied link to a publisher site but the user doesn’t have the necessary authentication token from the institution’s single sign-on service, then they will be bounced back for the username/password and redirected to the publisher’s site. GetFTR signaling that an institution is entitled to view an article does not mean the user can get it without proving that they are a member of the institution.
A key point that Ian raises is this:
One example of how this could suck, lets imagine that there is a very usable green OA version of an article, but the publisher wants to push me to using some “e-reader limited functionality version” that requires an account registration, or god forbid a browser exertion, or desktop app. If the publisher shows only this limited utility version, and not the green version, well that sucks.
Oh, yeah…that does suck, and it is because the library—not the publisher of record—is better positioned to know what is best for a particular user.
Ian asks, “Will google scholar implement this, will other discovery services do so?” I do wonder if GetFTR is big enough to attract the attention of Google Scholar and Microsoft Research. My gut tells me “no”: I don’t think Google and Microsoft are going to add GetFTR buttons to their search results screens unless they are paid a lot. As for Google Scholar, it is more likely that Google would build something like GetFTR to get the analytics rather than rely on a publisher’s version.
I’m even more doubtful that the companies pushing GetFTR can convince discovery layers makers to embed GetFTR into their software. Since the two widely adopted discovery layers (in North America, at least) are also aggregators of journal content, I don’t see the discovery-layer/aggregator companies devaluing their product by actively pushing users off their site.
It is also useful to reinforce Ian’s closing paragraph:
I have two other recommendations for the GetFTR team. Both relate to building trust. First up, don’t list orgs as being on an advisory board, when they are not. Secondly it would be great to learn about the team behind the creation of the Service. At the moment its all very anonymous.
Wow, I didn’t set out to write 2,500 words on this topic. At the start I was just taking some time to review everything that happened since this was announced at the start of December and see what sense I could make of it. It turned into a literature review of sort.
While GetFTR has some powerful backers, it also has some pretty big blockers:
I don’t know, but I think it is up to the principles behind GetFTR to make more inclusive decisions. The next steps is theirs.



